Framework and Business Logic Components
CHAPTER 4 Software Development Productivity
Generally, people who have no experience developing software tend to think that the development of software is the same as the manufacture of goods, but this produces tremendous misunderstandings. It is also wrong to think of software development productivity as something that can be easily measured in numerical terms. Furthermore, discussing software development productivity without actually getting involved with software development cannot be expected to yield useful results. It would merely lead to a discussion that makes no sense and leave the numerical terms of productivity standing alone and out of context. It would be utterly fruitless.
This chapter will start with a rather thorough analysis of what software development is and then try to examine the proper method of measuring its productivity. After that, it will reflect back on the history of software development thus far to see whether productivity is improving, and finally, it will explore methods for improving productivity.
In this chapter, the text seems to have become just a bit redundant, probably due to dealing with bloat within programs, i.e. redundant portions. Readers who feel that the content of this chapter is common knowledge should probably just skim through and read only those parts that interest them. In this chapter, we have written about matters that back up the content of Chapters 3 and 5, and therefore, if you agree with what has been written here, the purport of this book will be conveyed even if you skip this chapter. However, readers who are of the impression that the content of this chapter is not common knowledge probably should take the time to carefully read it.
4.1 What is Software Development Productivity?
Even if people in the position of managing software development think they would like to play some part in software development productivity, they do not necessarily have to know the details of development work. However, they do at least have to properly recognize what sort of work software development is. This section will start by looking at what sort of work software development is and then go on to deepen understanding about its productivity.
4.1-a Software Development is Design Work
It is said that software productivity is not improving in proportion to the dramatic improvements being made in hardware productivity. The meaning of this sentence is intended to rouse software engineers to action. This statement in itself should be accepted without protest, but we could interpret its meaning as noted hereafter.
We can consider productivity related to the manufacture of hardware (goods) as what is dramatically improving, and it stands to reason that what is not improving is productivity when human beings carry out design work of software development. Consequently, we can understand the above statement as saying, “The productivity of software design is not improving in proportion to the dramatic improvements being made in the productivity of hardware (goods) manufacturing.”
To begin with, the expressions hardware productivity and software productivity are vague. To clearly define their meaning, we must establish the separate categories of “design productivity” and “manufacturing productivity” for both hardware and software. In other words, we must make comparisons between hardware design, hardware manufacturing, software design, and software manufacturing. By doing so, we will recognize, if anything, what they have in common based on essential differences between design and manufacturing and the slim difference between whether the target is hardware or software. For example, if you were to compare support tools, you would find they correspond to each other, such as CAD (computer aided design) for supporting hardware design being equivalent to various types of editors and compilers that support software design, also a hardware simulator being equivalent to a software debugger. Once you realize this, you will see the real meaning of “the productivity of design is not improving in proportion to the dramatic improvements being made in the productivity of manufacturing,” whether you are talking about software or hardware.
To deepen understanding in this area, let’s start by clearly defining the meaning of the words “design” and “manufacture.”
“Manufacture” assumes that design has already been completed and means “the production of a physical object” that was clearly defined through design work. The manufacture of a car, computer hardware, a structure, or a printer is the production of some sort of object clearly defined by a design drawing, while the manufacture of software or a publication is nothing but the production of a floppy disk, CD-ROM, or bundle of bound paper containing a copy of the original.
Furthermore, “design” is something that clearly defines what is to be manufactured, i.e. it completely eliminates vagueness about what is to be made. The act of designing dispels any doubts about what will be produced at the manufacturing stage and leaves no room for creativity. Another way of saying this would be “design” is the preparation of everything so that not even one ounce of creativity will be necessary for what is to be manufactured (in this place manufacturing method details are a separate matter).
If you take a novel as an example, “design” is work wherein you develop an idea, collect material, write, polish, and then work out the binding. On the other hand, “manufacturing” is work wherein you set type to produce the original plate, run the printing press, and then bind the books.
Note that we distinguished between the work of clarifying requested specifications and the work of implementing them in Chapter 3, but the “manufacturing” process is what follows both of them. Furthermore, these two types of work can be perceived as “design” in the broad sense. If you want to distinguish between them, the clarification of requested specifications is what you do before “design” in the narrow sense and you can perceive the implementation (coming up with implemented figure) of requested specifications as being equivalent to “design” in the narrow sense.
Software development includes such work as planning/analysis, general design, programming, and testing whether it is based on a waterfall model or spiral model. Since we refer to programming within this work as manufacturing, misunderstandings arise, but if you think about it a bit, programming is definitely not manufacturing. The manufacturing process is the copying/burning of data onto floppy disks or CD-ROMs (software products) after what is to be manufactured is clarified. Since programming is nothing but work that clarifies what is to be manufactured (software), it is included in the design process. Thinking of it as being equivalent to work wherein you draw up design drawings would be appropriate.
To begin with, almost all software development is design work. Consequently, if we want to improve its productivity, we must come up with a plan for improving design work productivity. If you were to force the comparison of software development to a manufacturing process, even if we wanted to capitalize on the fruits of productivity improvements in manufacturing work, it would be no more than a mere wish. As discussed later in 4.3 “Is Software Development Productivity Improving?” it is difficult to apply a plan for improving manufacturing productivity to design work. You are free to compare software development to a manufacturing process, but we cannot recommend doing so because it merely breeds misunderstandings and fosters illusions.
4.1-b How to Measure Software Development Productivity?
Productivity is the “amount of products” divided by the “total work hours” spent in manufacturing or developing products and it means the amount of products per unit work hours. The value of productivity increases when you raise the amount of products or decrease total work hours compared with the former production method, and productivity is determined by the ratio of these two items (amount of products and total work hours).
Productivity = Amount of products/total work hours
First of all, we count only the hours directly spent by workers for the measurement method for total work hours. In the case of software development, the greater part of development cost is labor, so even if we only count that, there probably will not be a big error.
However, in the case of the process industry, which requires large investment in facilities, we must consider the cost of equipment. In short, to enable more precision, we should include the work hours that workers spent to develop and manufacture equipment. This is a reasonable way of thinking, but we are dealing with software development productivity here. Therefore, in order to simplify the discussion, we will calculate productivity using only the total work hours directly spent by work in development and manufacturing, based on the idea that the previously mentioned facilities are infrastructure for developing and manufacturing.
Total work hours can be easily dealt with in this manner, but how to measure the amount of products is a difficult problem. How to measure the amount of products in design work, like software development, is particularly difficult.
If you look into how to measure products in manufacturing work, this too is by no means easy. If you want to try comparing different types of products, for example, car manufacturing and bookmaking, how to adapt the criterion for the amount of products becomes a problem. If you attempt a comparison, the only choice seems to be a monetary amount converting each type of work into added value. It is generally difficult to compare the amounts of products when they are different.
For manufactured goods of the same type, for example, automobiles, you can measure (count) the amount of products by the number of vehicles. However, there are both luxury cars that require extensive manufacturing and economy cars that are more easily manufactured. If you measure the amount of products simply by the number of vehicles, productivity will be higher for economy vehicles than for luxury vehicles. That does not necessarily mean economy car manufacturing has better manufacturing technology for improving productivity than does luxury car manufacturing (such tendencies are sometimes seen). A fair comparison of productivity in which the amount of products is measured in product units will only be possible with the same type of manufactured goods that are of the same grade.
In the case of things for which only one, or an extremely small number, are produced, such as high-rise buildings that have a unique design, what units should we use to represent the amount of products is a particularly difficult problem. This means even if we compute productivity based on rough values, such as Building 1, Building 2, the data cannot be said to be meaningful because there is no way to compare it to anything else. If we assume that the total work hours for the construction of Khufu's Pyramid amounted to one million man-years, then productivity in that case would be 0.000001 building/man-years. However, this does not have numerical-term meaning for productivity; it is nothing more than the reciprocal of mere total work hours. Data with meaning for productivity will only result through a representation that is easy to compare with something else rather than units, such as Building 1, Building 2. We need an ingenuity that measures the amount of products using a common criterion, such as floor space or volume, even though this might ignore a building’s value in a certain sense.
Unlike with small-scale production, the comparison of productivity between the same types of manufacturing goods in the case of industrial goods that are mass-produced is easy. If you measure (count) the amount of products in units, such as Item 1, Item 2 and then compute productivity, you will end up with data with sufficient meaning, at least for those manufactured goods. For example, productivity data indicating that a certain automobile can be manufactured at a rate of 0.3 vehicles/man-day would serve as an indicator as to whether changing the manufacturing method of that automobile would be effective in improving productivity. This means such data would be a barometer for evaluating manufacturing technology for the automobile.
In this manner, productivity representing the amount of products in a number of units (count) has sufficient meaning in the case of repetitive work. However, in the case of small-lot production or products of different types or grades, productivity can only be compared if we find a common criterion suitable for representing the amount of products.
We have thus far looked into how to measure products in manufacturing work, but similar things can be said about the amount of products in design work such as software development.
Since software has normally been developed on an individual basis (please note that this book does not recommend this, but this is the way it is), the problems involving small-scale production resemble high-rise buildings that have a unique design. And there are various software products that take so much effort to be developed and those that don’t. Consequently, there is no way to make comparisons with anything else with productivity computed by the rough measurement (counting) of the amount of products, such as System 1, System 2. In this business system, even if you say productivity was 0.01 system/man-month, the numeric value only means production took a total of one hundred man-months and does not have any significance in terms of productivity. Enabling comparisons of productivity among different types of development demands that we find a way to represent the amount of products. We require ingenuity like representing the amount of products for a pyramid by means of floor space or volume.
There are a variety of proposals and arguments concerning this common criterion. They include many that might be seen as last resorts such as:
• With the number of program lines excluding comment statements, there is the problem that it can undergo any amount of padding, but we have no choice but to use it, because there is no other good criterion; or
• You should use a weighted score to measure the numbers of forms, report forms, records, and data items; or
• You should measure by the revenue generated by the products.
There are many variations even among ways of measuring that are similar to the number of program lines. There are also detailed debates as to whether counting the number of statements or the number of characters in a program is more exact. This book represents this common criterion using “the number of program lines excluding comment statements,” without entering into such debates.
4.1-c Minimum Information Content of a Program
We would like some sort of theoretical backing that will enable us to fully accept the way to measure the products of software development. The well-known Shannon's theorem, which forms the foundation of information theory, clearly defines the relationship between information content and channel capacity, and it is the theoretical backing for removing redundancy from within information. Accordingly, if we measure the amount of products using this “information content,” we should be able to get objective data that we can accept. In short, if we knew the minimum information content required to write (or transmit) a program for solving a problem of a certain scope, we could create a single definition of objective productivity by adopting that value as the amount of products. In simple terms, this minimum information content is program size when the program is the most compacted. In terms a bit closer to Shannon's theorem, the minimum information content is the number of bytes after the program has been skillfully compressed so as to reduce the bytes transmitted as much as possible when it is sent over a communication line. Note we use the term true productivity to describe the computation of productivity that adopts the minimum information content of a program as the amount of products.
After all this preparation, you will probably be shocked to learn that no algorithm has been discovered for determining the minimum information content of a program. Furthermore, just as no general solution exists for the well-known halting problem of the Turing machine that appears in computer theory (see Note 8); we noticed that there is no solution for determining the minimum information content of a program. Without a general solution, we can only determine the minimum information content in a practical manner by exercising our creativity for each individual program. In other words, we make the program as small as possible by utilizing the technique of eliminating unnecessary portions, grouping common portions into common subroutines and common main routines, and then compressing the program information (see Note 9). This work is extremely difficult, and it will likely take so much effort that it cannot even be compared with developing a program. Furthermore, since it is difficult to declare that a program cannot be made any smaller, we end up with a never-ending job. In short, determining the minimum information content is extremely difficult.
Accordingly, it is usual to adopt the number of developed program lines excluding comment statements as the amount of products to take the place of this. If this value is assumed to be proportional to the minimum information content, then we can regard it as productivity that has objective meaning. The number of developed program lines excluding comment statements and minimum information content certainly can be thought of as tending to be statistically proportional. However, if you take a look at individual development cases, there are both programs that have been tightly compacted and those that are filled with bloat (redundant portions). If we do not somehow estimate and compensate for the degree of bloat, we will end up misevaluating development as having increased high productivity without knowing we have an absurd program with a false bottom and padding.
Note 8: A Turing machine is a virtual computer employed when developing computer theory. It is so named because A. M. Turing devised it. Note that the A. M. Turing Award given by the Association for Computing Machinery (ACM) to individuals or groups that contribute to the computer field is also named after him.
The halting problem of the Turing machine refers to the problem of deciding whether a program that has been started will stop at some point or will continue running indefinitely due to complex loops. If we consider a specific program, we can sometimes come up with the answer to the halting problem. However, Turing has proven that there is no general-purpose algorithm that can come up with this answer no matter what program is considered (in other words, we cannot create a program that produces an answer to the halting problem). This theorem in the computer science world, which states, “You cannot produce an answer to the halting problem,” corresponds to K. Gödel’s incompleteness theorem, and it has become an example of the existence of problems that can never be solved.
Note 9: Currently being translated.
If we compare this to productivity for pyramid construction, the number of developed program lines excluding comment statements will be equivalent to the volume of the pyramid as measured from the outside. However, there are probably also pyramids that are densely packed with stone, as well as those filled with an enormous amount of space or bloat, so to speak. Assuming that, representing the amount of products using the criterion of apparent volume will not necessarily be appropriate. Pyramids containing space inside should be reconstructed into a minimum pyramid that minimizes apparent volume by filling it with stone, and then that actual volume (minimum information content) should be adopted as the amount of products. However, since reconstructing the pyramid would take an enormous amount of work, we have no choice but to use apparent volume to measure the amount of products. It would be nice to have a method for easily determining the actual volume of the minimum pyramid without the need for major reconstruction, but there is no such method for programs.
4.2 Various Ways of Measuring Software Development Productivity
There is no measurement method for software development productivity that everyone can accept. Accordingly, to create one that can be accepted even a bit, it would seem better to make comprehensive decisions through the use of multiple measurement methods rather than relying on just one. We will therefore introduce a number of measurement methods.
4.2-d How to Compensate Productivity that is based on Number of Program Lines
We will start by describing productivity as represented by the following formula that is widely used to indicate the results of the productivity of design work (software development).
Number of developed program lines excluding comment statements/Total work hours
This book refers to values calculated by this formula as plain productivity without any compensation. Plain productivity is nice because it can be easily determined, but there are negative consequences in relying on it. Namely, developing a compact, densely packed program will cause productivity to be evaluated as being low, while developing one that is full of space will cause productivity to be evaluated as being high. Adopting such an evaluation method will impede efforts to make programs compact and encourage the use of easy ways that inflate programs with bloat. Even if you assume that it is rare for programs to be padded to raise apparent productivity with bad intent, before you realize it, we will end up getting used to thinking that bloated programs are the norm. In fact, it appears we have already come to that point.
This sort of problem occurs because of the adoption of apparent volume (number of developed program lines) as the amount of products. To avoid this, we should adjust the amount of products by the degree to which a program is packed rather than using plain productivity as is. In addition, we should use “a productivity value that is completely eliminated of bloat, such as true productivity.” Note that this book refers to values adjusted from plain productivity as compensated productivity.
As for how to compensate productivity, we think simply subtracting bloat whenever it is found from the amount of products would be easy to understand. For example, whenever you found a space inside a pyramid, you would subtract it.
A specific example would be whenever you found unnecessary program steps; you would subtract that amount from the number of developed program lines. Furthermore, regardless of whether reuse had been enabled for common subroutines registered in the library, if you found duplication that was newly added, it is bloat, and therefore, that number of lines should be subtracted from the program that was developed.
There are a variety of software resources that can be reused. As we have made clear in this book, not only common subroutines, but also common main routines related to operation characteristics and data item components related to business specifications can be reused. Consequently, the principle of thoroughly reusing resources registered to component libraries should be applied to these as well. On the other hand, if you find out those common main routines, or data item components, routines equivalent to them, have been redundantly developed, you should make an adjustment.
Compensated productivity that can be determined in this manner can be represented as follows. Incidentally, we will point out the same representation for plain productivity too. Note that the “number of program lines actually developed” indicates a value greater than the “number of program lines actually required to be developed” by only the “number of bloat lines found.”
Compensated productivity
= (Number of program lines actually developed - Number of bloat lines found)/Total work hours
= Number of program lines actually required to be developed/Total work hours
Plain productivity = Number of program lines actually developed/Total work hours
The above mentioned compensation method is simple and easy to understand, but since bloat has to be detected manually, we run into the problem that some of it might be overlooked. In short, the value of compensated productivity will end up varying depending on the sensitivity of bloat detection. There will likely be times when we carelessly fail to find bloat or will not be able to detect parts we never suspected to be bloat in the first place. For example, even if we are not told about common main routines related to operation characteristics and end up redundantly developing that part, we might not notice it is bloat. Since we can only compensate when we notice bloat, compensated productivity will not end up being a productivity value from which bloat is fully subtracted, such as with true productivity. There is certainly no way to detect parts that no one has yet noticed, but the foundation of this method is to try to increase awareness about bloat, and to compensate for it whenever it is noticed. It would be nice if there were another method for strictly determining compensated productivity, but there is unfortunately no other ingenious way except for compensating as described above.
Apart from plain productivity, which is pretty much meaningless, I would like you to see that meaningful software development productivity cannot be easily measured in numerical terms.
There are a number of problems, including the fact that more than plain productivity, compensated productivity indicates a value closer to true productivity (productivity value from which bloat has been completely subtracted). Furthermore, the negative consequences that come from using plain productivity can be greatly mitigated by adopting compensated productivity. Plain productivity currently dominates, but we should quickly switch to compensated productivity. Although the troublesome compensation work, which was not necessary until now, might be a barrier to switching, it can be conducted concurrently with program review.
Topic 7: PC-Based Development and Review
I once stated at a seminar, “Compensation work for determining compensated productivity should be performed concurrently with program review,” but this just elicited puzzled looks. After looking into this, we discovered that program reviews are not being performed anymore. Out of the attendees there, only about ten percent where in the habit of conducting reviews.
Since computers were once expensive, the time when you could use them was limited. Accordingly, a lot of effort was put into reviews so that debugging could be finished in a short time. It is great how PCs have become commonplace and available for use at any time, but it seems that reviews have been forgotten.
For the record, a review is work wherein a program that has already been written is revised. It is equivalent to polishing writing so to speak. There is self-review conducted by a single person, but most often, review is conducted by several people affiliated with the development project. The purpose of a review is to find interface inconsistencies and bugs, but a review is also about information exchange among programmers. In short, it also serves as a setting for viewing beautiful programs and exchanging opinions on creating them.
Without information exchange, a program becomes a self-centered work and we miss chances to brush it up. And since common portions in each other’s programs are left unidentified, reuse is hindered. These are tremendous problems because even if you heavily use computer power, development personnel will not be able to catch up no matter how many people you add during the development of bloated programs. Determining compensated productivity should substantiate this.
Development firms that directly link values estimated in the unit of “man-months” may temporarily profit, but they will end up paying it back in maintenance work. In short, they will need even more manpower for maintenance. This might be good for firms that profit by selling maintenance services, but for those on the ordering end, it is a harsh situation that adds insult to injury.
Therefore, even if you are using a PC, a review should be performed. Unlike before, we now have an environment in which we can conduct reviews between people that are geographically separated by using a network, such as a WAN or LAN, and suitable groupware. It is really ironic that although we have such a great environment for conducting reviews, they are actually being conducted far less due to heavy computer use.
Incidentally, the aim of a review can also be achieved by refactoring, which springs from a slightly different viewpoint than reviewing. Consequently, if reviewing is the older of the two, then maybe refactoring is better. Based on this, we probably should have been asking, “Are you refactoring?” rather than “Are you reviewing?” Refactoring is not only the reduction of redundant portions in a program; it is also the enabling of reuse by transforming a program in specifically targeted situations.
4.2-e Implementation Verification for Determining Improvement Rate of Productivity
We have been recommending the combined use of multiple measurement methods to find a productivity value that can be accepted even a bit, but now, instead of questioning the absolute value of software development productivity, let’s focus on the relative value of how many times productivity will increase/decrease, i.e. the scaling factor, when certain seeds (materials, measures, mechanisms, and/or structures) are sown. We will use the term improvement rate of productivity to represent how much each seed improves productivity.
The improvement rate of productivity had the potential to be meaningful data that is clear and easy to understand. This value will become information for making a rational decision about the order in which seeds should be sown. It will be enough to get this improvement rate of productivity when evaluating what became of productivity as a result of sowing a certain seed. There is no need to go out of the way to determine the absolute value of productivity.
There are two methods for determining the improvement rate of productivity. Let’s start with the method for finding it by means of implementation verification.
At first glance, the improvement rate of productivity, due to certain seeds, may seem easy to measure by means of implementation verification. In other words, you may think that if the same development team develops the same development target, first by not sowing those seeds and next by sowing them, you would be able to determine the improvement rate of productivity (reciprocal of the total work hours ratio). For example, if you assumed that it would take two hundred man-months if those seeds were not sown and one hundred man-months if they were, then you could say productivity only doubled due to those seeds. This is nothing more than determining the improvement rate of productivity by means of implementation verification.
However, such implementation verification is not so easy. If the same team were to develop the same software twice, productivity would obviously be higher the second time because the developers would have remembered important development information from the first time. Reuse would be carried out naturally. In this situation, different teams would have to develop the same development target to get a valid measurement. The problem here is there would be no guarantee that both teams would have equal development ability. Accordingly, the need arises for having multiple teams develop the same thing and then taking the average value to get a value that is statistically meaningful. For example, we would have to conduct large-scale implementation verification in which we made ten teams develop without sowing those seeds, made another ten teams develop by sowing those seeds, and then compared their results. It would be like a test for verifying the effects of a new drug.
This measurement method may seem like a major undertaking, but it can produce highly precise measurement results. This is because, if we assume that the amount of products is the same without worrying about how to measure the products or how to detect bloat and adjust plain productivity, then we need only to compare total work hours. The problem with conducting this implementation verification is we get products of varying qualities, such as those with good/bad performance and those that are buggy/not buggy. Consequently, we will not get a fair measurement result unless we deal with such qualities as well. It is actually difficult to match the qualities of products, but it seems that we can determine a fairly pertinent improvement rate of productivity by setting up a concrete standard for software quality and then making comparisons after establishing a standard of attaining or exceeding a certain level.
This sort of implementation verification may seem extremely meaningful, but we have never heard reports of it being conducted. People probably avoid it because they consider it to be troublesome and a major undertaking. Alternately, they consider it to be unproductive, and therefore, do not apply to become members of such a development team. Above all, mounting cost is a drawback. However, like motor sports, which consume vast sums of money, improves automobile safety, the development race really does contribute to increased productivity. Implementation verification could likely be carried out smoothly if it were possible to appeal to playfulness and procure funding by increasing the number of people that approve taking pleasure in the development race.
First of all, software development depends almost completely on the parameter of human mental activity. And since this parameter, influencing productivity, varies widely in a variety of senses, we are always under its shadow, even if we try to measure the effects of each of the seeds. However, if we want to seriously measure the improvement rate of productivity, it seems appropriate that we conduct this sort of implementation verification. And as long as we do not conduct implementation verification with this level of detailed attention, it looks like we will not be able to accurately determine the improvement rate of productivity.
Based on this, I would like you to once again see that software development productivity and the improvement rate of productivity cannot be easily measured in numerical terms.
4.2-f Build-Up Method: Another Way to Determine Improvement Rate of Productivity
In addition to implementation verification, the build-up method is another way to determine the improvement rate of productivity due to the sowing of certain seeds.
The build-up method starts with a step that estimates effects in individual work, and then by means of a step that builds this up, it computes the total rate of work saving to determine the improvement rate of productivity. The latter build-up step will produce the same result no matter who does the computation, but the former effect estimation step cannot avoid relying on subjectivity and sensitivity. To determine the improvement rate of productivity under such adverse conditions, it is important to make an effort to be as objective as possible and shed light on what seems to be the basis. Accordingly, we recommend representing effect estimation as the product of the percentage of supported work and the percentage of work saving. Making this the product of two numeric values, rather than one, demands even deeper effect analysis, and if a dramatic difference arises compared to another person’s estimated value, analyzing that difference would also be helpful.
To determine the improvement rate of productivity, we should estimate the following two percentages, convert them into a ratio (where 100 % is 1), and then calculate the reciprocal of their product.
• Percentage of supported work:
(Indicates, as a total, what percentage of work those seeds support out of all development work for the software. In other words, totaled percentage of supported work, wherein software development work, extracting maintenance activities, will be 1, i.e. 100 %.)
• Percentage of work saving:
(Indicates what percentage of the work will be automated within the supported work. In other words, the percentage of work saving within the target work. For example, 100 % if complete work saving is possible, and 0 % if there is no support for it whatsoever.)
For example, if 5 % of the work accounting for 20 % of all development were supported, then by determining the product of each percentage, we would see that only 1 % work saving is possible. 1 % work saving means a productivity improvement of about 1.01 times (1/0.99 times).
The percentage of supported work and percentage of work saving are actually quite difficult to measure in numerical terms, so there probably is no other way than to boldly estimate it by relying on subjectivity and sensitivity. However, as long as the degree of roughness is at least 5, 10, 20, or 40 percent, we can likely come up with an estimate without much error. Even if we can accept that degree of precision, we still would like to measure by numerical terms.
However, among seeds that improve productivity, there are those that not only support specific work, but also affect the post processes. For example, seeds that support the clear definition of requested specifications not only improve the productivity of the work itself, but also have the effect of decreasing the need to redo post-process work. The rate of work saving for post-processes in such cases is similarly represented in the form of the product of the percentage of supported work and percentage of work saving, and then this is built up (accumulated) to calculate the total rate of work saving.
Incidentally, this computation method also seems usable for quantitatively theorizing the effect of productivity improvements by increased reliability. Since improving reliability makes it possible to decrease needless work spent in post processes, productivity can be improved.
Now when we actually try to calculate the degree of productivity improvement, such as tool improvements, on a per-seed basis, we are almost always disappointed by the extremely low values that do not reach one percent for most of the time. Telling yourself that every little bit helps and sowing many seeds that have a small effect is probably another way. However, since effective seeds have already been exhausted, it is really unfortunate that there are no more left with a substantial effect.
Please refer to Appendix 3 “Example Using Build-Up Method to Determine Improvement Rate of Productivity,” which gives an example of calculating the degree of productivity improvement by the build-up method.
4.3 Is Software Development Productivity Improving?
This section tackles the problem of whether software development productivity is improving. However, it is incredibly difficult to answer this question by producing hard evidence. Accordingly, we will make comparisons with manufacturing work productivity, and so on, while reflecting back on software development history to present circumstantial evidence as to whether software development productivity is improving.
4.3-g Why Has It Been Possible to Improve Productivity of Manufacturing Work?
For reference purposes, let’s begin by trying to look into the reason why manufacturing work productivity is improving.
Even in manufacturing work, the productivity of repetitive work where large numbers of copies are made is reaching considerably high levels through the mass production of industrial goods. In the manufacturing of many industrial goods, machines rather than human beings already carry out a major portion of manufacturing work. Accordingly, human beings perform nothing more than ancillary work. Through today’s advanced technology, although costs may be high, even the complete automation of manufacturing work is already possible in many areas. For example, if you visit a plant that manufactures robots, you can observe robots that are automatically manufacturing certain types of machinery. You can also see with your own eyes how such robots themselves are being automatically manufactured day and night by other robots.
Since total work hours in which human beings are directly involved will approach zero, if adequate facilities investment is made, productivity (based on certain infrastructure) can be become nearly limitless.
However, since the monetary amount of investment diverted for infrastructure improvement can be suppressed according to how much goods of a certain price level can actually be manufactured, it has become a battle to see how far productivity can be raised within a limited range of resources. Another way of saying this is, although productivity can be raised, doing so inexpensively is difficult.
Why do you suppose it has been possible to raise productivity to a high level when manufacturing a large number of copies? A major factor therein, of course, is the build-up of ideas and efforts by a large number of people, but you could also say it was also due to the following two factors of copy manufacturing.
The first is productivity that can be expressed in objective numeric terms. When a new proposal is made for improving productivity, we are able to accurately grasp its degree of effect and degree of side effect, and thus there is no room for the emergence of mistaken beliefs. New proposals can be accurately and clearly evaluated.
The second is that manufacturing, no matter how you look at it, is an activity in which mechanical processing is possible requiring no creative intellectual work. Actually, whenever you try to mechanize the manufacturing process for some sort of goods, there will likely be a variety of problems in carrying it out, and solving them will likely require the intellectual work of manufacturing engineers. However, as already indicated by many past mechanization achievements, there is no doubt that almost all such problems can be solved technologically.
4.3-h Why is It Difficult to Improve Productivity of Software Development?
In contrast to manufacturing productivity, design work, such as software development, does not have the above-mentioned two factors that are helpful in improving productivity.
First of all, it is difficult to express productivity in objective numerical terms. To obtain a common view about productivity, there is no escaping, to a certain extent, the reliance on subjectivity and sensitivity when determining such numeric values, even if you exert your best efforts to adopt the most scientific technique possible and make a decision through the combined use of multiple methods. Large-scale implementation verification is required so you will not have to rely on subjectivity and sensitivity. This was already discussed in 4.2 “Various Ways of Measuring Software Development Productivity.” Consequently, when a new proposal for improving productivity is made, what degree of effect it really has is not entirely clear. Under such circumstances, there is a tendency for people to think that their technique is the best.
Second of all, design includes work that is difficult to process mechanically. The main portion of design is thinking up what you will try to make and then fleshing it out so that anyone can manufacture it. Since the majority of such intellectual work cannot be mechanically processed by any means, there is no other way but having human beings take care of it.
What computers can do is either to perform calculations according to formulas set up by human beings or to support human design work in an auxiliary or indirect manner. Under usual circumstances, we would like to leave the main portion of design work to computers rather than human beings. However, the majority of design work carried out by human beings is not of a type that can be represented by numeric expressions. Furthermore, even figuring out which approach should be taken to make a computer take care of such work is like groping blindly in the dark at present. In contrast to this, we can confidently state that mechanical processing is possible in manufacturing for the most part.
4.3-i Improvement of Software Development Productivity in the Good Old Days
Under such circumstances wherein it is definitely not easy to improve productivity, you might wonder whether software development productivity is improving. The general consensus is “software design productivity is not improving in proportion to the dramatic improvements being made in hardware manufacturing productivity.” Even the vast majority of people involved in software development probably think productivity has hardly improved at all if they were to reveal their true feelings.
To underscore this problem, we will try to definitively show that software development productivity has hardly improved at all. Then we would like to decide whether productivity is improving based on whether we can present a counterargument to what we have shown.
Since there must be some sort of seeds (measures, mechanisms, and/or structures) for improving productivity, we’d like to start by trying to prove whether picking up such seeds have really improved productivity by briefly reflecting back on software development history.
Based on this, we get the following argument stating it was possible to improve software development productivity in the good old days.
Everyone will admit that the evolution of programming languages from machine language (first generation) to assembler language (second generation) and then to compiler language (third generation) has produced easily discernable productivity improvements. And the use of interactive computers and the development of editors have doubtlessly had an impact in their own right. For example, if you estimate that switching from assembler language to compiler language reduces by 5/6 of the work that occupies a total of sixty percent of development, and then the resulting work saving for all development would be fifty percent, thereby improving productivity by a factor of two.
As you can see, because there were a number of seeds (measures, mechanisms, and/or structures) that made computer processing easier and had a major effect in the early days of computer development, incorporating them into tools made it possible to greatly improve productivity.
The above-mentioned argument therefore makes sense, and we can thusly accept the fact that software development productivity improved in the good old days. We can even accept the fact that the utilization of compiler languages raised productivity to a certain level, and that level became the industry norm.
However, if you look into the matter thereafter, it appears that seeds that had a major effect in the good old days were soon exhausted, and productivity from that point barely improved at all. Perhaps this is what has been causing the stagnation of tool productivity over the past ten years or so. In other words, it seems we have not been able to raise productivity to as high a level as the previous industry norm.
Do you think a counterargument can be presented for this? Doing so will require us to discuss seeds that have a major effect and clearly indicate their effect. Since 4.2 “Various Ways of Measuring Software Development Productivity” and Appendix 3 “Example Using Build-Up Method to Determine Improvement Rate of Productivity” provide an in-depth description of the evaluation method for seed effects, we should use this information to present a counterargument.
Do you, the reader, know what seeds we could use for our counterargument?
4.3-j Productivity Improvement Plan Based Only on Tools
The author, who became a minor development support tool vendor about ten years ago, should have presented a counterargument to this based on that occupation. Unfortunately, it is not possible to present a counterargument to this. Although we would like to present a counterargument to this, the seeds that make computer processing easier and have a major effect have already been exhausted. Consequently, in the wake of seeds that enable mechanical processing in design work to replace what humans do, there are no good seeds left.
After studying a group focused on the average value of the number of program lines that a single person could write (complete) in a day, it seems during the past ten years or so, that value has been confined to between twenty to thirty lines and has barely increased. You would think that by now we would be able to write even a few more programs, but the industry is stuck at this low norm. Since this value depends on the speed at which human beings can carry out intellectual work, we cannot expect any major growth as long as human beings themselves are conducting the main portion of design work. Of course, there will be variation in the speed at which each person can produce a program, and we can also expect speed improvements through training. It would seem that such factors of variation would be hard pressed to raise the average value by a factor of two or three overall. Another matter all together would be a mutation that dramatically improved the development ability for software and spread to the entire human population.
Based on this, we would like to pin our hopes on seeds that have computers carry out the intellectual work that forms the heart of design. In short, it would be nice to have computers rather than human beings carry out the main portion of design work. However, this is far out of the realm of possibility due to the current state of technology. Once we accept this fact, there are two things we can do, as follows:
• Incorporate the seeds sown so far into tools, or in other words, extract what can be processed mechanically from design work and have computers carry it out; or
• Aim for a cooperative effect that accompanies support by tools.
In the former case, unfortunately, the only seeds left have almost no effect whatsoever. However, since we say that every little bit helps, even supporting seeds that improve productivity little by little, is probably not a waste. Then again, we can no longer expect a major effect.
The cooperative effect of the latter is the effect created by having computers carry out mechanical processing. For example, word processor capabilities not only offer support that makes editing work, such as the addition, modification, and deletion of text easy, but also support the creation of difficult documentation. No one wants to read illegible handwriting to which lots of corrections have been made, but when you see nice word processor output, polishing the writing becomes enjoyable and you want to unify the format whenever you find parts that are not aligned. Doing so certainly increases productivity, although it is difficult to measure the effect in numerical terms. Computers are only as effective as their users.
4.3-k Providing a Pleasant Software Development Environment
If there have only been slight productivity improvements in terms of the average value of the number of lines that a single person writes (completes) in a day, you might wonder what on earth tools have done, or if that is all tools for increasing productivity are capable of. Let’s respond to this here.
Almost all tools make human work much easier by taking over work that is grueling and troublesome for them. The diagram editor of CASE tools reduces the load of tiresome diagram revision work, word processors and program editors take the trouble out of editing work, such as additions, modifications, and deletions, and documenters extract a great deal of documentation from program information (as a result, human beings no longer have to check for inconsistencies between program information and documentation). Aren’t these really helpful tools? Combined with the cooperative effect that comes with tool support, they really make development work much easier.
From this perspective, you can see how the seeds that have been incorporated into tools over the past ten years or so, have been pursuing the goal of making software development work more pleasant, more than contributing to productivity increases in the true sense of the term. For example, automobile development aimed at offering pleasant spaces after basic car functionality matured. Similarly, providing a pleasant software development environment for software development support tools too is a crucial topic. Also, there is no doubt that this is something that increases productivity in the broad sense. However, it is not a productivity increase in the strict sense as we imagined being measured, as discussed in 4.2 “Various Ways of Measuring Software Development Productivity,” but instead is mere fanfare.
Topic 8: How Much Do Tools Improve Productivity?
The author, who is a minor development support tool vendor, sometimes is asked an annoying question. Some people will point out a specific tool and ask how much it improves productivity. The annoyance comes from the fact that even if they ask about the improvement rate of productivity for a specific tool, they themselves are the ones who hold the answer to that question.
We have already introduced two methods for determining the improvement rate of productivity. It does not matter whether you use implementation verification or the build-up method, but in either case, there are many things that must be made clear.
Now I would like to introduce how to find the effect of the seeds that support the drawing of diagrams using tools, as illustrated in Appendix 3 “Example Using Build-Up Method to Determine Improvement Rate of Productivity.” I will explain that in the case of development projects with a high rate of error in comprehending the requested specifications, productivity can be increased to a certain degree, but in other cases it cannot. As a result, we can only determine the improvement rate of productivity if we know the error rate in comprehending the requested specifications in this example. Furthermore, the degree of benefits of tools will differ depending on whether the development project is using the technique of writing things down in diagrams. As you can see, the improvement rate of productivity by tools will vary widely depending on the nature of the development project and the development techniques employed therein.
Regardless of what will come in a hundred years from now, there currently are no tools that automate all development work. Consequently, we must assume that human beings must first and foremost pursue jobs using tools. Once we do this, what sort of actions human beings take comes into question, and the improvement rate of productivity will vary depending on that.
Accordingly, the author answers in the following manner when asked about the improvement rate of productivity for a specific tool.
Generally, tools increase productivity when they are used in a manner that suits their purpose. Therefore, when selecting a tool, it is important to not only listen to and agree with explanations about where it excels, but also actually give it a try so you can get a feel for whether it is suited to your development project. Generally speaking, there are no tools or other aids that can declare they increase productivity x times in every case. Only by trying a tool out to see how it will work for your business program development will you come to see to what degree productivity can be raised.
To paraphrase President J.F. Kennedy, “Ask not how much a tool can raise productivity for you; ask how much you can raise productivity using that tool.”
4.4 Improving Software Development Productivity
We have so far discussed the negative opinion that software development productivity has hardly improved at all over the past ten years or so. If we tentatively accept this, does that mean the way to improving productivity is completely blocked? Well, if it is difficult to raise productivity, we should probably ask whether there is a way for harnessing an effect similar to productivity improvement. In other words, we should repose the problem by saying what can be done if we say that the development speed of a densely packed program is limited.
4.4-l Improvement Rate of Productivity by Reuse
It is a bit misleading to say this, but most programs developed thus far are fortunately inflated with bloat, and thus, it is a good idea to focus on it. Measures for reducing bloat and eliminating needless work, i.e. promoting component-based reuse, raise productivity. This is a way for improving productivity not with tools alone, but rather by the combination of tools and components.
Interestingly enough, when you promote component-based reuse, in extreme cases you will encounter situations in which you can produce (develop) a software product with certain features even without writing (developing) a program. Consequently, we need a renewed awareness of software development productivity. Here, we would like to recall “Topic 1: Dreaming of the “Golden Egg” Business Package” that was discussed in 1.1 “Differences between Custom Business Programs and Business Packages.”
To begin with, the word “productivity” does not click with the approach of thorough reuse without software development. People who are misled by the sound of the word “productivity” tend to fall into plain productivity for its own sake. They simply think they should increase the amount of products. Since changing your mindset to promote component-based reuse, i.e. increasing the rate of reuse (rate of non-production), rather than thinking only about increasing the amount of products will decrease total work hours spent on development, it is another way to actually improve productivity.
Accordingly, we will introduce the improvement rate of productivity by reuse as a gauge representing how much productivity has actually improved. Since you can eliminate needless work if you remove bloat from a certain piece of software, i.e. you thoroughly reuse what can be reused; this gauge indicates how much productivity will actually improve. Accurately determining this value requires the previously discussed implementation verification for both the non-reuse case and the reuse case. However, if a rough value is sufficient, you can use the following formula:
Improvement rate of productivity by reuse = Plain productivity/Compensated productivity
Since the value of this formula is the same as the number of program lines actually developed divided by the number of program lines that really need to be developed (value of the formula shown below), it indicates the improvement rate of productivity by reuse if we assume that the work time per number of program lines (time taken to develop the program) is fixed.
Number of program lines actually developed/Number of program lines that really need to be developed
While we are on the subject, let’s try using the formula to determine the improvement rate of productivity by reuse for two special cases. The first one is a case of all bloat. In this case, compensated productivity is zero and the improvement rate of productivity by reuse is infinite. The second one is a case of no bloat whatsoever. In this case, plain productivity and compensated productivity coincide. Consequently, the improvement rate of productivity by reuse will be 1. A value of one means that since there is no bloat, productivity cannot be increased through reuse. From another point of view, if there is bloat, there will be room for improving productivity through reuse. That is why we have focused on the fact that most of the programs developed thus far are inflated with bloat.
4.4-m What Does Improving Productivity by Reuse Mean?
This book has so far discussed on many occasions the improvement of productivity through reuse, which means an improvement rate of productivity by reuse of above 1. You could reword this by saying that since reuse will enable you to get rid of needless development work that produces bloat; it will end up improving productivity.
Note that the value of compensated productivity will not end up increasing, even by aggressively pursuing component-based reuse, because compensated productivity is a criterion that does not consider bloat to be a product, i.e. a strict criterion that regards waste as waste. On the other hand, plain productivity even includes bloat among development products, and can thus be called a rough criterion so to speak.
Just as the question “How much can tools raise productivity?” is generally meaningless, the question “How much can reuse raise productivity?” too is generally meaningless. However, when you aim to develop a specific business program for a specific development project, both of these questions will come to have meaning. And there are even cases where just a little improvement in a certain development project will exert an eye-opening effect on productivity improvement.
For example, to get the benefits of reuse, turning redundantly developed portions into common subroutines will exert an eye-opening effect on development projects that are not accustomed to the use of common subroutines. In addition, to raise productivity, switching to a development method that distributes templates of main routines related to operation characteristics and then copies and appropriately revises them is also effective for projects whose developers develop multiple individual procedures related to operation characteristics.
As you can see, the degree of productivity improvement by reuse will vary depending on the degree of component-based reuse carried out. Essentially, the lower the degree of reuse in a development project, the greater the effect. Furthermore, some sort of an effect can be expected as long as the development project is not carrying out one hundred percent component-based reuse. Note that one hundred percent reuse means preparing a business program simply by combining components.
When you look at it this way, there are almost no development projects that carry out one hundred percent component-based reuse, and thus, we can see room for improving productivity a great deal. In short, we should promote reuse by the combining of components (or by tools, such as a 4GL, that include components). In contrast to this, we have previously discussed that we do not know how to continue improving productivity because productivity improvement plans based only on tools have already used up the seeds for doing so.
4.4-n Two Methods for Improving Productivity by Reuse
As Figure 4-1 shows, there are two methods for component-based reuse. Adopting either one will produce better results than a development method that lets developers do it their own way. Letting them do it their own way tends to end up with haphazard results, in return for the joy each developer gets by the creative endeavor of making new discoveries. Therefore, it is sure that copying with a known lineage is still better than haphazard methods. And it is much better to systematically employ reuse by referencing than copying.
Reuse by copying
Can increase development speed for programs.
However, it results in bloated programs.
Seen as high productivity because a large number of programs can be developed.
However, it increases resources that must be maintained, thereby making maintenance difficult.
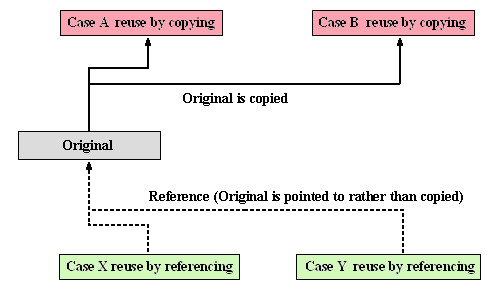
Reuse by referencing
Number of lines to be developed for a program tends to be cut in half or a third.
(Example: Enhancing common subroutine libraries and then thoroughly reusing them.)
Results in compact programs.
Apparent productivity will not improve, but productivity in the true sense will improve.
Resources that must be maintained decrease, making maintenance easier.
Figure 4-1: Two Methods of Reuse
One method of component-based reuse is reuse by copying. It increases program development speed regardless of whether the program is bloated.
There are a variety of conceivable methods for increasing speed if you are developing a program that is not densely packed. For example, you could teach program expressions that are often used in order to cultivate veteran developers who can repeat them off the top of their head. If repeating them off the top of the head is difficult, another conceivable method is learning by rote each program fragment that will serve as an example and then recommending that the appropriate things be copied. Among such methods, you should probably most of all recommend such things as copying the main routines related to operation characteristics.
If you were to include the copied portion in the count of newly developed lines in this manner, apparent productivity (plain productivity) would dramatically increase. Doing so would not increase problems beyond conducting development one’s own way as has been the tradition. The problem of increased software resources filled with bloat, causing heavier maintenance loads, still remains as always, but copies (bloated programs) for which the lineage is known are easier to maintain than haphazard bloated programs that are reinvented by developers who do things their own way.
Another method is reuse by referencing. It aims for developing programs that carry out equivalent processing with fewer newly developed lines. Bloat is extensively removed in this method.
This enables the development of a program that carries out processing equivalent to what has been possible thus far by using fewer newly developed lines (half to a third less than what was required by one program thus far). For example, you would enhance general subroutine libraries and then teach developers to extensively reuse them. However, under the present circumstances in which the main general subroutines have already been brought to light, and the grouping and reuse of common subroutines has become commonplace, it would probably be difficult to use even fewer newly developed lines than before. That is certainly true, but since the common main routines and data item components discussed in this book have not been used much thus far, using them will likely have a considerable effect. In short, if we enhance common main routines and data item components and then aggressively reuse them, there will be grounds for creating programs that carry out equivalent processing with fewer lines.
For the record, reuse by referencing is an approach that pursues no copy reuse rather than bloating, and since it does not inflate programs, it does not improve apparent productivity (plain productivity). Nevertheless, it still has the same effect as improving productivity.
4.4-o Evaluating the Two Reuse Methods
Now let’s try to evaluate these two methods.
• Reuse by copying
• Reuse by referencing
Reuse by copying is an approach that gets developers accustomed to reuse and recommends systematic copying. Therefore, bloat resources will accumulate. And since copied resources will be changed over time, their lineage will be more and more difficult to understand, and eventually the copied portions will have to be considered new software resources independent of the copy source. In other words, this means resources that have to be maintained will increase, leading to a heavier maintenance load.
Reuse by referencing is similar to this in the fact that it gets developers accustomed to reuse, but it does not recommend reuse. It is an approach that changes software into an easy-to-reuse structure, resulting in the elimination of bloat resources. For example, even though this approach reuses ‘Business Logic Components,’ it does not increase software resources that have to be maintained.
From a maintenance standpoint, reuse by referencing is preferable by far. Furthermore, reuse by referencing has future possibilities. Just as mechanization in manufacturing is a way to approach infinite productivity, thoroughly pursuing reuse by referencing in software development can do the same thing. By enhancing ‘Business Logic Components’ fully, the necessity of new development will decrease to nearly zero. This is more than possible using the current technology.
Of course, the way to infinite effect will probably not be easy. Just as infrastructure for mechanizing manufacturing processes on a per-manufactured-good basis is required in industrial goods manufacturing, the infrastructure of a set of ‘Business Logic Components’ on a per-application-field basis is also required in reuse by referencing. There are probably also issues such as continued efforts for enhancing ‘Business Logic Components.’ However, there is no doubt that reuse by referencing substantially rationalizes software development.
4.4-p Reuse Stages and the Two Methods
As shown in Figure 4-2, there are three stages of development in component-based reuse for a typical business program in the business field.
Traditional Business Program (First Stage)

Business Program Developed Using Fourth-Generation Languages (Second Stage)

Componentized Application (Third Stage)

The shaded portions are those that are actually reused or become easier to reuse when covered by ‘Business Logic Components.’
Figure 4-2: Expansion History of Component-Based Reuse
Most development projects reuse general subroutines by finding out common portions. The reuse of such subroutines has already become the norm. A business program developed by such projects at least reaches the first stage, and from twenty to thirty percent of the program can be covered by the reuse of general subroutines. Obviously, even if more subroutine reuse were recommended for such projects, it would not be possible to improve productivity any further. And even if it were possible, only a very small productivity improvement would occur compared to what we failed to reuse.
Incidentally, there seems to be a fair number of projects that do not reuse common main routines related to operation characteristics. Such projects can increase productivity by starting to reuse common main routines. Business apps brought to the second stage in this manner are likely covered twenty to thirty percent by the reuse of general subroutines and thirty to forty percent by the reuse of common main routines. Furthermore, productivity can be improved by only the amount common main routines were newly reused, i.e. the amount of increase from the first stage to the second stage.
There is a way to start the reuse of data item components in projects that attempt to carry out reuse even more thoroughly. Business apps brought to the third stage in this manner are likely covered twenty to thirty percent by the reuse of general subroutines, thirty to forty percent by the reuse of common main routines, and the rest by data item components. In short, they are turned into componentized applications. However, going from the second stage to the third stage does not increase productivity that much when developing the first version of a business program. Productivity increases in the phase where the first version of a business program (i.e. a componentized application) is reused. Examples would be customizing the first version of a business program for another customer, or performing maintenance on the first version of a business program.
Now let’s take an in-depth look at the process from the first stage to the second stage. There are two methods for reusing main routines. One is “reuse by copying,” which distributes templates of main routines related to operation characteristics and then copies and appropriately revises them. The other is “reuse by referencing,” which reuses common main routines by means of a 4GL (tool that includes components) and a fill-in system (combination of components and tools). Note that you can say development by means of a pre-generator (software tool) that we discussed in “Topic 6: Tools for a Componentized Event-Driven System” in 3.2.3 “From SSS to RRR Family” is reuse by copying and development by means of a post-generator (software tool) is reuse by referencing.
You can improve productivity in a similar manner no matter which method you adopt. However, since reuse by copying increases maintenance load, reuse by referencing should be used by all means. You will better understand this difference in maintenance load if you consider an example of when changes must be made to the original. With reuse by referencing, changes only have to be made to the original, but with reuse by copying, all programs developed by copying the original must be changed.
We have thus far discussed the method for turning a typical business program in the business field into a third stage componentized application. We think you will be able to see how doing this will dramatically improve productivity since almost no development products have yet to attain one hundred percent component-based reuse.
Topic 9: Improvement Rate of Development and Maintenance Productivity
This book has examined productivity targeting only development work, i.e. productivity that does not take maintenance work into consideration. However, considering the fact that the term maintenance hell frequently pops up, it is also crucial to take measures to prevent being inundated by maintenance work (including adding/changing features and fixing bugs) that is two to three times more time consuming than development work. The actual percentage of maintenance work varies depending on a variety of circumstances in each enterprise’s information department, but from the perspective of maintenance cost, it normally accounts for a large percentage as a fixed cost and cannot be ignored.
Note that the following discussion of the improvement rate of development and maintenance productivity will cover improvement rate of development and customization productivity by replacing the word maintenance with the word customization. Consequently, we ask that you read the following paragraphs from both the viewpoint of maintenance and customization. For example, the following discussion is very important for businesses that customize business packages because productivity targeting customization work is a key factor influencing profit.
Now we will examine not only the improvement rate of productivity targeting development work alone as we have done so far, but also the improvement rate of productivity targeting maintenance work. Note we will refer to the former as the improvement rate of development productivity (IR of DP) and the latter as the improvement rate of maintenance productivity (IR of MP). In addition, we will refer to the improvement rate of productivity through the entire lifetime as the improvement rate of lifetime productivity (IR of LP).
The following relationship exists between these three improvement rates of productivity:

(1 + α) / improvement rate of lifetime productivity
= 1 / improvement rate of development productivity
+ α / improvement rate of maintenance productivity
In the above formula, α represents the maintenance ratio. This is the scaling factor that tells us how many times the total work hours that were required for development will be spent on maintenance. For example, if we let three times the total work hours of development be the time spent on maintenance, then the value of α will be 3.
For reference sake, let’s try to evaluate the improvement rate of lifetime productivity by applying the above-mentioned formula to a specific case. Since the above-mentioned formula is hard to understand intuitively, presenting an example in numerical terms will make it easier to understand.
Let’s say the total work hours of development is 10,000 hours and total work hours of maintenance is 30,000 hours. This means the value of α will be 3. Let’s try to calculate whether improving development productivity five times or maintenance productivity two times is more effective in this case. According to the above-mentioned formula, the former improvement rate of lifetime productivity will be 1.25 and the latter improvement rate of lifetime productivity will be 1.6, and thus we see that improving maintenance productivity two times is more effective.
We can prove this as follows. In the former case, work that previously took 40,000 hours ends up taking 32,000 hours (10,000 x (1/5) + 30,000), but in the later case, it ends up taking only 25,000 hours (10,000 + 30,000 x (1/2)). Consequently, you can see how improving maintenance productivity two times is more effective.
There is a tendency to question only the improvement rate of development productivity when trying to improve software productivity, but doing so is apt to lead to errors in selecting the improvement method. By rights, we should question the improvement rate of lifetime productivity. And since whether you should make an effort to improve development or maintenance depends on whether the value of α is greater than or less than 1, it is important not to make errors in how you distribute your efforts. When α is greater than 1, i.e. a so-called maintenance hell is assumed, striving to raise the improvement rate of maintenance productivity more than development productivity will be more effective in improving the improvement rate of lifetime productivity. I think this is a very common-sense decision, but perhaps we often forget or ignore such rational decisions these days.
Incidentally, among seeds that improve productivity, there are those that have an effect on development work and those that have an effect on maintenance work. Therefore, to find out the effects of each seed, we need both the value of the improvement rate of development productivity and the improvement rate of maintenance productivity. For example, if we represent seeds that result in beautiful program structure using the two values of one percent for the improvement rate of development productivity and ten percent for the improvement rate of maintenance productivity, then we can clearly comprehend their effect. Furthermore, we can determine which seeds we should select to raise productivity based on whether the value of α is greater than or less than 1. When the value of α is greater than 1, we should emphasize seeds that improve maintenance productivity, and when it is not, we should prioritize seeds that improve development productivity.
The general tendency, thus far, has been to be totally preoccupied with development productivity and neglect maintenance productivity. Consequently, this neglected maintenance productivity seems to be stuck at a low level and the seeds for producing a major effect have still not been fully gathered. If this is the case, sowing effective seeds for maintenance should raise productivity over a lifetime.
However, when sowing seeds that will improve maintenance productivity, we often need to consider matters from the outset of development because cheap tricks alone cannot result in improvements. (For example, component-based reuse by ‘Business Logic Components.’) This makes it necessary to switch to a resource architecture that employs “business logic components.” Such a switch will reorganize resources that have to be maintained, thereby reducing bloat and dramatically improving maintenance productivity.
Copyright © 1995-2003 by AppliTech, Inc. All Rights Reserved.
![]()
AppliTech, MANDALA and workFrame=Browser are registered trademarks of AppliTech, Inc.
Macintosh is a registered trademark of Apple Computer, Inc.
SAP and R/3 are registered trademarks of SAP AG.
Smalltalk-80 is a registered trademark of Xerox Corp.
Visual Basic and Windows are registered trademarks of Microsoft Corp.
Java is a trademarks or registered trademark of Sun Microsystems, Inc.
===> Chapter 5