| Framework and Business Logic Components | Postscript Appendix 1 2 3 4 5 |
Postscript
Although a number of short to mid-range (in the two – twenty year range) allopathies have been thus far applied to business program development work, it appears that nothing like “the silver bullet” has been found. By all rights, we should strive for “the true automation of business program development,” which is likely to be made possible in the future (albeit in the long-run, possibly around a hundred years from now). However, when reflecting on this fragile reality without solid feasibility, after writing this book, I feel that the “component-based reuse” outlined in this book seems to be “the silver bullet” more than ever.
Tools Already at Mature Stage:
Since the support tools for business apps are at their mature stage, no innovative improvement can be expected to come out in the foreseeable future. The situation could best be described using the analogy of climbing a hill that has a steep cliff. The gradual routes to the hill have already been completely developed. Up to the hill, a powerful engine called a computer works effectively. However, although minor routes to the hill will continue to be developed, that does not help facilitate the development work for business programs a lot.
True Artificial Intelligence Technology Has Not Been Seen:
To develop business programs, it is necessary to climb up the steep cliff that rises on the hill. With flexible human intelligence it is possible to climb up the hill, but it is too steep for the computer to challenge by itself. The technology that can utilize the powerful engine to its fullest has not been discovered. Although many challenges have been made so far to enable the computer to climb up the cliff in various ways, none of them were successful.
It seems that the steep cliff on the hill continues boundlessly. If we strove for “making the computer automatically generate application programs in the true sense,” we would be bound to face this steep hill, regardless of which route we choose. Intellectual, high-level work that humans do cannot be handled with either “the upper process intellectual support tools for business program development,” or “the reverse engineering of business programs,” because of the sheer hill. It is known that even the Y2K problem, in which the problem was limited, could not be solved automatically.
The dream tool that could perfectly generate business programs automatically is compared to alchemy in the Middle Ages. If ever developed successfully, the tool would have a tremendous impact on the computer industry. This leads to seemingly sensational people showing up every once in a while claiming, “I generated gold!”
As basic research proceeds, the steep cliff that blocks the routes will be identified, and it may be realized that it is impossible to generate gold because it is an element. However, if the research proceeds further, the technology based on nuclear physics would appear, which in fact enables alchemy. That is when the future computer would be able to climb up the steep cliff on its own, instead of humans. Although it may happen some hundred years from now or even further in the future, I think it is a matter that will be solved in that time span. It is not something that can be solved simply by makeshift ideas.
Component-based Reuse is a Viable Solution:
If considering what we can do based on concepts like these, I presume the component-based reuse formed by ‘Business Logic Components’ is most suitable. Even though only humans can climb up the steep cliff on the gradual hill, once we have climbed up there, it will be possible to throw down a wire-rope, thereby taking advantage of the computer engine. This approach is different from the computer itself climbing up the cliff, so it is sufficiently feasible with software products of the current technological level.
Look at Current Business Environment:
Aside from the future outlook, now let’s take a look at the current business environment.
This book was written right in the middle of a recession. Looking at the internal causes, I noticed that chronic bloat, just like the one mentioned in the main text, was lurking underneath. Hence, might it be a chance for big business to promote streamlining and resolve the bubble condition?
It is foreseeable that we will lose any competitive advantage if we keep on mass-producing a large amount of software products without considering customization and maintenance. This is because as more and more business packages with special customization facilities are supplied, that perfectly fit a range of business programs at reasonable prices based on ‘Business Logic Component Technology,’ we are getting into an era of harsh natural selection. Meanwhile, this trend is also being boosted by the international competition in the ERP package business that raises an awareness of business packages.
In the course of time, the processes regarding business program development will be totally changed, and the division of labor will be promoted between development firms of business packages with special customization facilities and customization firms that tailor the products of the former firms to customers’ specification requests. In other words, it is the division of labor between firms that componentize and firms that reuse.
Anticipating this outlook for the industry, I would like to recommend that those who are concerned with business program development in the business field consider the following.
• If you have expertise of business programs in a particular business or field, it would be beneficial to start a development firm of business packages with special customization facilities by tailoring the programs into business packages with special customization facilities and supplying them to customization firms.
• If you have expertise of business programs in a particular business or field, it would be beneficial to start a development firm of business packages with special customization facilities by tailoring the programs into business packages with special customization facilities and supplying them to customization firms.
• If your firm’s business system gets in a predicament as exemplified in a maintenance hell, it would be recommended to switch to a sophisticated resource architecture that employs ‘Business Logic Components.’ This will enable the firm not only to avoid the maintenance hell, but also to sell business packages with special customization facilities.
For any one of these ways, ‘Business Logic Component Technology’ is essential. If you seek a business opportunity in resolving bloat, I strongly recommend that you employ this technology.
You can access the web-address below to obtain program samples of ‘Business Logic Components’ of this book. Also, I welcome your opinions and questions regarding this book, which can be communicated at the email address therein.
Lastly, I sincerely thank Ryusuke Shibata, a former president of Woodland Incorporation, who developed SSS, and Tsukasa Oonishi, a chief developer, for providing precious help to us in showing their development theory of SSS. Besides being thankful, I respect their creativeness. Also, their contributions to us in giving invaluable opinions in developing RRR tools have greatly eased our task of writing. Moreover, I would like to thank Ryuji Asada, the chairman of the company, and Jyoji Ozaki, an executive, who eagerly recommended us to write this book, without which the book would have never been written. I offer them our genuine gratitude.
Drafts of this book have appeared on the previously mentioned web site for about two years. I appreciate the encouragement and comments from those who read it. Especially, I thank Professor Masashi Yoshida for offering suggestions for improving over two hundred points.
November 2003
Yasuhito Tsushima
p.s. Please mail your opinion to me.
Appendix 1 What Does Running a Program Mean?
In this appendix, I explain what it means to run a program as well as its related issues.
Running a program means carrying out “something” in a lapse of time just like reading a book or playing a musical instrument. What is meant here by “something,” is for a human’s eyes to follow letters on each page to understand meanings as in the case of reading a book, for his or her eyes to read music notes while making sounds as in the case of playing an instrument, or for a computer’s CPU to compute tasks as it follows instructions of the program as in the case of running a program. Simply put, there is a device called a CPU in a computer that follows sentences just as a human’s eyes trail letters or music notes. However, the computer does it at an incredibly high speed that can never be exerted by humans; it computes tasks as it processes some millions or even tens of millions of sentences in a second. This is what makes computer power so great.
Now, we can assume that a music note instructs us what sound to make. Since the musical performance is to make sounds by interpreting notes, each note can be assumed to instruct what sound to make. Correspondingly, it can be presupposed that sentences in a program instruct what kind of computation to perform such as doing additions or comparing numbers. Accordingly, those sentences are presumed to be executable.
While in music there are codes that command to repeat playing or those that command to jump to certain places (different from ones described earlier that command to make sounds), in the program there are those imperative sentences that direct to repeat computing or those that direct to jump to certain places (different from ones described earlier that command to compute tasks). These codes or sentences with different functions from the aforesaid ones are there to control the flow of music or the flow of the program. Also, the control structure in this book is the instructions that control the flow of programs.
It is conventional to use some programming language in program development. The program language is different from natural language and has no exceptions in grammar and little vocabulary. It is, so to speak, a simple language that only gives instructions to a computer. Although having these differences, they have some things in common, and hence, have common expressions. For example, just like writing sentences in natural language, developing a program is called “writing,” “describing,” “making,” “creating,” or “structuring.” Yet, given only a few mistakes in programming, the CPU will not process what we intended it to do. The CPU does nothing but what is exactly commanded, nor does it give consideration to our intention. Therefore, debugging is required, which checks whether the CPU functions in a different way from what we intended it to do and correct the program if needed.
Due to the small vocabulary of the programming language, there are times when the computer language cannot communicate complicated expressions. Under this kind of circumstance, there is a mechanism that defines subroutines that correspond to new words and simplifies the complicated expressions. This can be regarded as the structure of component-based reuse. Just as we can contract a sentence by using words with a complex meaning, utilizing subroutines can shorten a program. Also, utilizing subroutines is termed “calling.”
Since the speed at which the CPU processes sentences goes beyond some millions to tens of millions per second, it seems that a small program is executed instantly. However, because we can make a program loop many times by controlling its flow, some technological calculations, albeit small, take a fast CPU over an hour to execute. On the contrary, business apps in the business field do not generally perform complex calculations like those technological ones. Instead, the CPU is expected to deal with a large amount of data in the business field, and hence, it mostly performs similar processes repeatedly.
To deepen an understanding of programs, it would be a shortcut to read programs written by other people or to write programs yourself. For example, if you have a widespread PC with a Windows OS, it is easy to write a program and execute it, using a visual development support tool, such as, Visual Basic of Microsoft Corporation. Visual Basic has functions not only for professional programmers but for hobby programmers as well, so it is a good choice for novice programmers to begin with. In addition, since it is advantageous to be familiar with event-driven systems in order to understand this book, it is recommended to use a type of Visual Basic that adopts an event-driven system.
Appendix 2 General Features of Business Applications in the Business Field
In this appendix, I list the three most conspicuous points that describe what kind of general features business programs have.
• There are a wide variety of business programs in the business field.
What is included in a business process depends on a mixture of factors, such as the history of each company, corporate strategies, the power-balance of departments, enterprise characteristics, types of products or services, industry customs, industry characteristics, the creative activities for differentiation and so on. So, it varies company to company. Therefore, a business program developed for Company A cannot be applied to Company B without modification.
Also, in response to a high NCA (Need for Creative Adaptation) in the business field, often, business packages are developed that can be customized to either Company A or B by specifying parameters. Nonetheless, there are frequent situations where Company C orders specification change requests that cannot be adequately managed just by specifying parameters.
• Business programs in the business field process various kinds of data.
Business programs in the business field normally deal with thousands of kinds of data, and it is conventional to call each of them a data item and identify them with data item names. For instance, they are clearly identified with the data items, such as “product code” or “sales date.”
• Business programs in the business field process a large amount of repetitive data.
Although business programs in the business field deal with not only a high volume of data, but also many types of them, they are simple and repetitive data. These kinds of data are, as an old trick, stored in containers called records. Records are the containers that are stored with correlated data items. Thus, if you build many records, you can store lots of repetitive data.
Moreover, by applying the program procedure for a certain record to many others, it becomes possible to process a large amount of records one after another in order to process that record as requested. Also, while a record is being processed, it is put under the critical condition of a possibility to be altered, and so exclusion control is needed to prevent accesses from the outside. In addition, to write several records to non-volatile memory, such as disks, each time a form is processed, transaction control is required.
On the contrary to business programs in the business field, in the technological field, very profound calculations are done based on a few data; it can be likened to a deep narrow hole. Applying the same comparison to business programs in the business field, we can imagine street stalls at a festival, which have a wide entrance and a shallow depth. This is because with the programs that comprise a business program, calculations for each data item are not awfully complicated, but there are a vast number of data items.
If you consider how to divide business apps with these kinds of characteristics, and how to correspond them to data items, you could be convinced of the contents of this book.
Appendix 3 Example Using Build-Up Method to Determine Improvement Rate of Productivity
When you estimate the improvement rate of productivity by the build-up method, there are some parts for which we have no choice but to depend on our subjective views or feelings. How influential those subjective factors are can be realized if we actually do the estimation. In this appendix, I report the processes of estimating the benefits of one of the seeds (materials, policies, facilities, and mechanisms) for reference when attempts like that are made.
General explanations of how to estimate the improvement rate of productivity in terms of the build-up method can be found in 4.2 “Various Ways of Measuring Software Development Productivity.”
Here, I selected some seeds that require consideration during the estimation or, in other words, seeds that are difficult to estimate. It is one of the popular seeds slotted in CASE tools, that is, the support for the task of writing various diagrams with upper process support tools. This seed is something that helps clarify requested specifications in the broad sense and, concretely, something that acts as a word processor to write diagrams. Also, since the seed has both direct and indirect work saving effects, we estimate each of these as the product of its percentage of supported work and its percentage of work saving.
Let’s estimate the direct benefits first. The work of clarifying requested specifications sometimes accounts for about 20 percent of the whole development work, and it includes a wide range of tasks such as interviews with customers and end users. Considering that the diagram making work is part of that entire work, the percentage of supported work should be approximated, at the most, at 5 percent of the whole development work.
Opinions are divided on how to estimate the percentage of work saving regarding this. It is possible to view it as a word processor for drawing diagrams that merely supports revision work and nothing more. What is drawn as a diagram comes up in humans’ minds, and no support is provided for what kind of diagram comes up in their minds. From this viewpoint, it seems that the benefits derived from this support are limited. Yet, this seed makes one think that rewriting is not troublesome, which results in the psychological effect of reducing one’s reluctance to find overlooked ideas. There may be some other accompanying effects. Thinking this and that, let’s suppose the percentage of work saving by this seed is 40 percent. With that, the percentage of direct work saving by this seed can be estimated by multiplying the percentage of supported work, of about 5 percent, and the percentage of work saving of 40 percent, together, which is equal to 2 percent.
Since this value of 2 percent is an estimate for direct supports, we need to include indirect supports in the calculation as well. Specifically, we also need to calculate the benefits of the implementation work of requested specifications after diagrams are made. If wasteful work that is incurred in post processes that are caused from the inadequate clarification of requested specifications, there should be an indirect support in that it reduces such wastes. Simply put, productivity is improved through this process.
The indirect benefits are calculated by multiplying the percentage of supported work by the percentage of work saving after they each are obtained, as were for the direct benefits. First, we suppose that the percentage of supported work is about 80 percent of the whole development work. Then, as for the percentage of work saving, its value varies depending on whether or not it is a development project in which many mistakes are often made in interpreting requested specifications, and also depending on when these mistakes are found. With a development project with many mistakes, the value of indirect benefits should be larger since there is more room to improve its productivity. With that, let’s assume that the probability rate of making mistakes in interpreting requested specifications is X, and that we found those mistakes right in the middle of a project. On these assumptions, we must have conducted wasteful work of 0 to 0.8 X, and we should be able to save 0.4X waste work.
Having grasped the above explanations, you are ready to compare the indirect benefits before and after this seed is adopted.
Before the seed is adopted, namely when you were creating diagrams with a pencil and an eraser, if, for instance, we made 20 percent mistakes (simply put, assume X = 20 %), you must have done 8 percent wasteful work in post processes on the average (80 % × 20 % × 1/2).
After this seed is taken up, let’s assume that the probability rate of making mistakes in interpreting requested specifications decreases from 20 percent to 15 percent through the adoption of support tools for creating diagrams. In this case, the wasteful work can be reduced from 8 percent to 6 percent on the average (80 % × 15 % × 1/2).
Therefore, by utilizing this seed, we can save 2 percent of wasteful work on the average.
Expressed in the aforesaid, prescribed form, given the percentage of supported work is approximately 80 percent and the percentage of work saving is 2.5 percent (mistakes are reduced by 5 percent, and they are found in the middle of a project), the rate of indirect work saving is 2 percent as the product of them.
Building up these benefits (or accumulating them), we can obtain the rate of work saving of 4 percent by adding up the direct rate of 2 percent and the indirect rate of 2 percent. Refer to Figure A3-1.
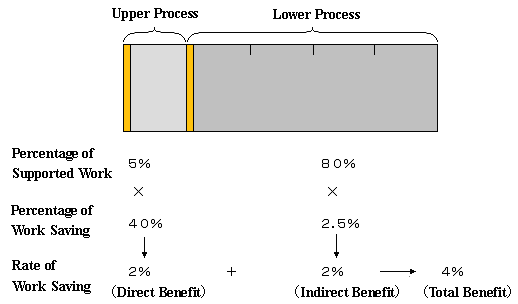
An example of the calculation for the rate of work saving when handwriting is changed to CASE tools for diagram writing work in a development project in which approximately 20 percent of mistakes are expected on average in interpreting requested specification:
Figure A3-1: Value Obtained for Rate of Work Saving
Although we assumed that the probability rate of making mistakes is 20 percent, development projects with a higher rate have more room for productivity improvement, and vice-versa. That is to say, it is normal that improving productivity of a development project for which various attempts have been already made for the improvement is not easy.
Also, in this appendix we estimated the benefits, assuming a development project that has already adopted the technique of utilizing diagrams. But, in a development project with no such technique adopted, we can expect more benefits by putting together that technique and those tools.
Please note that I am not claiming that an exact value for productivity improvement for diagram writing support was calculated. The above calculations involve various assumptions, so looking at only those values can lead to misunderstanding. Those calculations are intended simply to show the calculation method. I simply wish to draw the reader’s attention to the process of estimation, and I would just like you to refer to them when you estimate the improvement rate of productivity for some seed. Now, it’s your turn to pick a seed and try the estimation for it.
Appendix 4 Demarcation of Figure and Ground When Recognizing Something
When a human perceives an object, an internal mechanism seems to function in identifying it with some kind of concepts or images. In this case, the demarcation is made between the figure and the ground (background) so that we can perceive it.
The picture in Figure A4-1 is “Vase/Faces Drawing (Optical Illusion),” which is famous for allowing two types of perceptions. When regarding the white portion as the figure (then, the black portion becomes the ground), you can perceive the picture as a vase; however when taking the black portion as the figure (then, the white portion becomes the ground), you can perceive it as two faces.

Figure A4-1: Vase/Faces Drawing (Optical Illusion)
In conventional software development, subroutines are considered a figure in general, and common subroutines have been aggressively created in most of the development projects. However, there has been no such viewpoint from which main routines are considered the figure, so I suspect that no effort has been made to find common main routines. With the latter perspective, we may find common portions that have not been found by perceiving things from a different angle.
This is related to the perception ascribable to the inversion of conceptions, such as the inversion of control in terms of object-orientation.
In the meantime, the relationship between the main routine and the subroutine is a relative one rather than an absolute one. Thus, when you pick one routine, it may be a main routine that calls other routines, while at the same time it could be a subroutine that is called by other routines. With this dual characteristic, we sometimes see this misunderstanding, that is, the idea that we should think of making only subroutines as has been done without considering main routines. The point here is the perspective in finding common portions, not the implementation method for subroutines.
As for the implementation method, if you create a principle main routine consisting of a one-line program, it is possible to make all the other routines subroutines. This is because when there are things that are considered main routines, it is very easy to change them into subroutines (those that are called by the principle main routine); accordingly, it is obvious that we can transform all of them into subroutines. In this regard, they can function sufficiently as subroutines. However, doing this does not necessarily help find common portions that have not been found.
What is important is the perspective that facilitates finding common portions. When making the demarcation between those that call and those that are called to find common portions, we paid attention only to the commonality of those that are called. For this reason, we could not see the commonality of those that call. We could not, of course, because we did not try. Paying enough attention to the commonality of those that call, we can gradually see common portions; for example, it becomes obvious that skeleton routines of the fill-in system, operation bases that implement certain operation specifications, 4GL operation bases, GUI operation bases, and the like, are all common main routines. It is simple once we know the trick, but if we do not find it, common portions are often overlooked.
When common portions of those that call are found, it is totally up to you how to implement them. It is conventional, however, to build a structure for the common portions of those that actually call in such a way that it involves local main routines and subroutines within. This is comparable to the fact that there are local main routines and subroutines in the common portions of those that are called, i.e. in conventional subroutine structure.
Appendix 5 Generalized Construction Technique for a Reuse System of Componentized Applications
In this appendix, I first explain the process by which I derived the generalized construction technique for a reuse system of componentized product on the basis of the three requirements for a practical and effective component-based reuse system. I then show evidence for the theorem that if a certain software product can be constructed as a componentized application according to this generalized construction technique, or in other words, if there is an RSCA that complies with this technique, then the system truly can fulfill the three requirements.
The three requirements for a practical and effective component-based reuse system involve the following.
• Software products must be built up solely by combining components;
• The system must be able to meet all customization requests; and
• Large numbers of developers must systematically benefit from component-based reuse.
Also, the generalized construction technique for a reuse system for componentized applications should:
• Partition the area that software products cover into low NCA areas and high NCA areas.
• Cover all low NCA areas by using ‘Business Logic Components’ or ‘Software Components’ that provide the following quality (i.e. quality required of a ‘Black-box Component’):
- Ability to meet all envisioned requests in areas that must be covered by selecting components from component sets and specifying parameters (generality).
• Cover all high NCA areas by using ‘Business Logic Components’ or ‘Software Components’ that provide all of the following four qualities (i.e. qualities required of a ‘White-box Component’):
- Easy retrieval of desired components (retrievability).
- Number of components that must be revised is limited (locality).
- Size of each component is suitable (suitable size; suitable granularity).
- Each component is easy to decipher (readability).
Appendix 5-a Process by Which Generalized Construction Technique for a Reuse System of Componentized Applications Was Derived
The generalized construction technique for a reuse system of componentized applications was derived in the following way.
In the business field at least, application programs are rarely built solely by general subroutines because general subroutines cover only low NCA (Need for Creative Adaptation) areas and leave high NCA areas untouched. Thus, to cover high NCA areas, some kind of new “components” like ‘Software Components’ other than general subroutines are needed. In the meantime, rather than try to cover all the low NCA areas only with general subroutines, we usually need to use them together with common main routines.
Having assumed that, we forecasted that we would need to use some types of ‘Business Logic Components’ or ‘Software Components’ together and, consequently, started to seek ‘Software Components’ other than general subroutines.
Now, if you think why high NCA areas cannot be covered by general subroutines, you will probably find that it is because of the premise that they do not allow program customization. Then, if they allow program customization, they should be able to cover high NCA areas.
Thereupon, taking the above consideration as a hint, I decided to classify components into those that never allowed program customization and those for which you are resigned to performing program customization. Then, we named the former the black-box component and the latter the white-box component.
After that, in an attempt to investigate the appropriate use of each component, we tested them on the second and third requirements of the above three.
If you build a component-based reuse system solely by black-box components, large numbers of developers can systematically benefit from that component-based reuse, but the range of customization requests that you can handle will be limited.
On the other hand, if you build a component-based reuse system only by white-box components, any customization request can be met, but it is likely to become a system with which systematic component-based reuse is difficult.
In either way, it was not easy to make the second and third of the three requirements compatible with each other. So, I divided a program into low NCA areas and high NCA areas to grope for a way to handle each of them independently. That is, I planned to manage each of those areas separately either with black-box components or white-box components.
First, I estimated that low NCA areas could be covered by black-box components. Then, I considered what to do to make this happen.
It would be problematic that using black-box components results in limiting the range of customization requests. However, since low NCA areas were where we could expect what kind of customization requests are likely (or areas that are easy to handle), we should adequately handle them only with parameter customization. Thinking this way, I concluded that it would be okay if black-box components were equipped with generality, the quality that is explained below. Also, I decided to call this quality the quality required of a ‘Black-box Component.’
- Ability to meet all envisioned requests in areas that must be covered by selecting components from component sets and specifying parameters (generality).
If black-box components have this quality, they can meet any envisioned customization request in areas that must be covered by selecting components from component sets and specifying parameters, which means that black-box components can cover low NCA areas. Also, black-box components with this quality are consistent with the definitions of ‘Business Logic Components’ and ‘Software Components’ of this book. In this book, this black-box component is expressed as ‘Black-box Component.’
Next, I supposed that high NCA areas needed to be covered by white-box components so that any customization request would be met. The problem here was how I could make white-box components “systematically reusable for large numbers of developers.”
Then, breaking down this problem, the below four qualities came up, and I thought that if white-box components had all of them, a large number of developers would be able to reuse them systematically. Putting together these four, I decided to call them the qualities required of a ‘White-box Component.’
- Easy retrieval of desired components (retrievability).
- Number of components that must be revised is limited (locality).
- Size of each component is suitable (suitable size; suitable granularity).
- Each component is easy to decipher (readability).
If we can build a program consisting of ‘White-box Components’ with all the four qualities, systematic reuse by large numbers of developers becomes possible. This is because, in response to a certain customization request, desired components are retrieved quickly, the number of them is limited to one or two, each one of them is not too large, and they are easy to decipher. In other words, thanks to retrievability, we no longer go astray due to modules that the original developers arbitrarily partitioned, and thanks to locality, suitable size, and readability, we no longer have to painstakingly decipher the whole program. Although the decipherment of a program is required a bit, it is within the permissible range for large numbers of developers to reuse it systematically. Conversely, it would be easier to understand if you think in the way that we require sufficient retrievability, locality, suitable size, and readability of ‘White-box Components’ in order to make the decipherment work within the permissible range.
Therefore, if there is the ‘White-box Component’ with all of these qualities, systematic reuse by large numbers of developers is possible. Then, because white-box components are components for which you are resigned to performing program customization, they can cover high NCA areas. Also, ‘White-box Components’ with all of these qualities are consistent with the definitions of ‘Business Logic Components’ and ‘Software Components’ of this book. So, in this book this type of white-box component is noted as ‘White-box Component.’
Although I listed the four qualities above as the qualities required of a ‘White-box Component’ and created the component equipped with all of them, there might be other appropriate combinations of qualities. But, I did not go too far with this. If you are interested, you can go further.
This is the process by which the generalized construction technique for a reuse system of componentized applications (RSCA) was derived.
Here please note. To be exact, what covers low NCA areas can be ‘Black-box Components,’ ‘White-box Components,’ or even the combination of them. But it is desirable to cover them with ‘Black-box Components,’ if possible, since it is better not to need the maintenance of a program. To cover low NCA areas, we should use as few ‘White-box Components, with which maintenance of a program is needed (or may be needed), as possible, and use ‘Black-box Components’ whenever you can (you should be able to).
But, as described earlier, high NCA areas cannot be covered by ‘Black-box Components.’
Appendix 5-b Proving Theorem of Satisfying the Three Requirements
In this section, I show evidence for the theorem that if a certain software product can be constructed as a componentized application according to the generalized construction technique, or in other words, if there is an RSCA that complies with this technique, then the system truly can fulfill the three requirements.
The first of the three requirements, the one that says that software products must be built up solely by combining components, is satisfied. This is because low NCA areas in the areas covered by software products are covered by black-box components that meet the qualities required of a ‘Black-box Component,’ and high NCA areas are covered by white-box components that meet the qualities required of a ‘White-box Component.’
Hearing this abstract explanation, you may not picture concrete images of “what it means to divide software product coverage into low NCA areas and high NCA areas,” or “whether the fact that components cover certain areas is the same as the idea that a software product is built up solely by combining components.” If you feel that way, refer to examples in “5.2 Technique for Constructing Component-Based Reuse Systems and an Actual Example” to aid your understanding.
As for the second of the three requirements, which states that the system must be able to meet all customization requests, let’s consider it in terms of both the low NCA area and the high NCA area.
With regard to the low NCA area, you should be able to speculate as to what customization requests are likely. Then, because the black-box components that cover that area meet the “qualities required of a ‘Black-box Component,’” or have the quality (generality), “ability to meet all envisioned requests in areas that must be covered by selecting components from component sets and specifying parameters,” the second requirement is fulfilled.
The high NCA area, on the other hand, is covered by white-box components for which you are resigned to performing program customization, so any request can be handled. Consequently, the second requirement is met.
For the last of the three requirements, the one that claims that large numbers of developers must systematically benefit from component-based reuse, let’s check it in terms of both the black-box component and the white-box component.
With the black-box component, since we can utilize it only by specifying declarative information with clear-cut meaning as viewed externally without deciphering the inside program, the third requirement is satisfied.
As for the white-box component, although the decipherment of a program sometimes may be required, depending on customization requests, by meeting the “qualities required of a ‘White-box Component,’” the systematic reusability by a large number of developers can be guaranteed. Therefore, the third requirement is fulfilled.
To describe this in depth, in response to a certain customization request, desired components are retrieved quickly, the number of them are limited to one or two, each one of them is not too large, and they are easy to decipher; therefore, a large number of developers can systematically reuse the components. As explained earlier, due to retrievability, we no longer go astray due to modules that the original developers arbitrarily partitioned, and thanks to locality, suitable size, and readability, we no longer have to painstakingly decipher the whole program. Although the decipherment of a program is required a bit, because they are easy to decipher, and the range does not augment, decipherment is acceptable.
With all the explanations described above, I have shown evidence for the theorem that if we can build a software product as a componentized application according to this generalized construction technique, or in other words, if the reuse systems of componentized applications (RSCAs) based on this generalized construction technique exist, that system must fulfill the three requirements.
What should be noted here is that it is not guaranteed that RSCAs like this can be built in every field. Rather, I can only say that there exist actual cases of RSCAs based on the generalized construction technique in the business field, and that we can build RSCAs according to this generalized construction technique, at least for general application programs in the business field. However, we cannot guarantee, for example, whether the software that supports the human genome project can be built based on this generalized construction technique. Similarly, even in the business field we may not be able to build RSCAs based on the generalized construction technique in specific areas. Regarding this issue, you can refer to the explanation of the component-enabled portion in Chapter 5 “What are ‘Business Logic Components’?”
Finally, let’s consider the theorem that I just described above in reverse order, that is, the proposition of whether or not we can say that it is needed to employ the generalized construction technique in order to make the component-based reuse system meet the three requirements. Unfortunately, this has not been proven. In this book, I only explained the process by which the generalized construction technique was derived. Although I presume that only this generalized construction technique, or its somewhat revised versions, can satisfy the three requirements, this presumption has not been officially proven. So, there may be other construction techniques. If you are interested, why don’t you study them? Then, if you come up with a new construction technique, try to prove that your construction technique can satisfy the three requirements too.
Copyright © 1995-2003 by AppliTech, Inc. All Rights Reserved.
![]()
AppliTech, MANDALA and workFrame=Browser are registered trademarks of AppliTech, Inc.
Macintosh is a registered trademark of Apple Computer, Inc.
SAP and R/3 are registered trademarks of SAP AG.
Smalltalk-80 is a registered trademark of Xerox Corp.
Visual Basic and Windows are registered trademarks of Microsoft Corp.
Java is a trademarks or registered trademark of Sun Microsystems, Inc.
===> References