Framework and Business Logic Components
CHAPTER 3 Software Development Support Tools
This chapter will present an overview of general software development support tools, such as fourth-generation languages (4GLs) and CASE tools, and then try to compare them to SSS tools using ‘Business Logic Component Technology’ and general tools.
The development of SSS tools themselves was carried out without much study of worldwide tool trends. In retrospect, however, we now know that while capabilities, such as those in general tools were being built in, some capabilities where made to project out. In short, SSS tools were not so special as to be incomparable to other tools.
Accordingly, we set out to make the RRR family the best component-based reuse system in the world by studying worldwide tools and incorporating the more advanced aspects of other tools as part of the investigation of an RSCA. Note the RRR family is a refined version of SSS.
While reading this chapter, please also refer to Chapter 4 “Software Development Productivity.” After wondering whether to put the content of Chapter 3 or 4 first, we finally decided to arrange the chapters as you see here. We probably should have written this book so that you could read the material in these two chapters together.
3-a Upper Process Support Tools and Lower Process Support Tools
Tools that support software development are categorized as upper process support tools and lower process support tools depending on which development processes they support. There are also cases where three categories including middle process support tools are used, and there are even more detailed classifications.
The segmentation of development work is probably an effective means for finding good development procedures, but defining development processes too narrowly is a problem. The reason for this is even if we divide development processes into segments, work will not necessarily be easy for human beings by following such segmented processes. As will be discussed in 4.1 “What is Software Development Productivity?” software development is entirely different from manufacturing hardware (goods) on a conveyor belt. Just because intellectual work during software development is cut up into small chunks does not mean it will become easy. To begin with, the portion of software development that can be processed automatically can be handled by computers, so there is no need to have programmer go out of their way to do it. Consequently, the work that human beings should carry out during software development is that which is intellectual, and partitioning such portions is almost meaningless.
However, since leaving the categorization of development processes ambiguous may also result in a hotbed of illusions, some sort of categorization is necessary. This book categorizes them simply as upper processes and lower processes and provides clear definitions for each category as follows.
This book defines upper processes as those wherein people understand the real world (and its periphery) that will be the target of computer processing and clearly articulate the image of a business system as requested specifications, and lower processes as those that implement the requested specifications, or in other words, processes that create software for building a business system based on the requested specifications. Furthermore, it defines upper process support tools and lower process support tools as tools that support the work in each of those processes.
These definitions always presume that human beings will be at the center of the work. Tools that did not require any human intervention whatsoever, i.e. tools that automated all development work, would be of a much higher level than the support tools defined here.
3-b Perceptions of Upper Processes and Lower Processes
Two proposals on how to perceive the relationship between upper processes and lower processes (see Note 5) have been made. The first is the waterfall model. The perception here is that processes flow from higher to lower ground like the water falling over a waterfall and never reverse course. It is normal to reverse course from lower to upper processes in actual development work, but if it is small enough that it can be ignored, this perception is fine.
Taking this perception of development one step further, the ideal for development based on the waterfall model is making sure you never have to go back from a lower to an upper process. An example of where this would be ideal is large-scale development by a large number of developers. Since it is said that the amount of work for dealing with specification changes increases in proportion to two times the number of developers, particular care is taken not to produce specification changes in development by large numbers of people. The eradication of going back from a lower to an upper process is sought in such cases, and perfecting work in upper processes becomes a crucial issue. This results in a focus on upper process support tools. Note the upper process support tools will be described in-depth in 3.1 “Upper Process Support Tools.”
Note 5: This book uses the terms upper process and lower process because they are widely used. However, these terms are tainted by the waterfall model and include a nuance that brings to mind the term upper class. To avoid being influenced by such nuances, it would probably be best to use terms like the clarification process for requested specifications and the subsequent implementation process.
Another way to perceive upper processes and lower processes is the spiral model. This perception considers development as proceedings much like going down a spiral staircase; the upper processes and lower processes go round and round. This concept holds that revision and reflection will lead to progress, but there is also an element of waste here when you have to go back from a lower to an upper process because of a development mistake.
This may seem contrary to what you would expect, but you could also consider development based on the spiral model to be ideal. People who think the waterfall model is ideal will probably object to this by saying, “How on earth can you think that going back from a lower to an upper process is ideal?” Even if tolerating going back from a lower to an upper process is sometimes unavoidable, it is wrong to call it an ideal. However, we are supporting the spiral model because there is a human engineering idea that idealizes adjusting to human characteristics. This concept too is quite feasible. For one thing, when humans create magnificent works, they are constantly revising what is being made. Consequently, even in software development, revision is what makes it possible to make magnificent products.
Development that idealizes the spiral model shifts to the lower process and creates a prototype system for the time being only after forming an image, to a certain degree, in the upper process. Prototyping support tools (discussed later) play a major role therein. Note that this sort of development method is known as rapid prototyping or rapid prototyping development.
As for how the first prototype system made is handled, there are cases where it is created then abandoned and cases where it goes through a number of versions leading up to the full-fledge system. The following paragraphs will try to depict development for the latter cases.
Once the stage where the first version of the prototype system has been created, the upper process is returned to. Next, unlike the first time, the prototype system already exists to a certain degree, so it can be used to find inconsistencies with the real world and refine requested specifications. Requested specifications are easier to clearly define when there is a system you can see with your eyes rather than one that only exists in your mind. Once such requested specifications are clearly defined, the lower process is shifted to, and then changes are made to the prototype system based on the latest requested specifications.
By going back and forth between the upper and lower processes in this manner, the system will be updated, and once it has gone through one hundred versions for example, a business system that can actually be used will be completed.
Such a depiction may give the impression that upper and lower processes are quite far apart, but since there are also cases where these processes are repeated in a short cycle much like a painter making one brush stroke only to change it, they can be seen as being in perfect harmony. With that in mind, you can probably understand why this is no exaggeration.
Topic 4: End-User Development and the Spiral Model
End-user development refers to the end user, who is the user of the business system, carrying out development work, not development specialists (custom business program development firms and enterprise information department staff). Since end users normally already have a good understanding of the real world and its periphery that will be the target of computer processing, upstream processes can be greatly reduced when end users carry out development. Consequently, it would seem good for end-user development to carry out development based on the waterfall model. However, it is development based on the spiral model that is more common because it is extremely difficult for end users to pin down an image of the business system they want at the very first stage when they have nothing developed yet. Generally, as a business system starts taking shape, various requests start bubbling up.
In one story we heard from someone who had experienced end-user development, the person was able to realize the effect of really utilizing a computer while breaking in the business system that had been created. The system was for supporting the taking of customer orders by phone and by providing the support described hereafter, it gave customers a good impression about the company and enabled high sales growth.
That business system offered support such that immediately after an order where a customer says something like, “That product was great, so this time give me twice as many as last time,” the company representative could answer, “Okay, so that’s n units of product x.” It also offered support so that the company representative could liven up the conversation by saying things like, “By the way, how did you like y? Isn’t your stock about to run out? How about ordering some now?” After some functional tuning of this business system, it was able to make customers think that all the company’s staffs were constantly thinking about them no matter who at the company picked up the phone.
Awareness and extensive use by end users who will answer the phones and operate the business system was crucial for achieving this, but the business system end also required update after update. You could say that integrating the staff that answers the phones with the business system mandates the adoption of a spiral model development method.
3.1 Upper Process Support Tools
In this section we will attempt to take a deeper look into upper process support tools that help us to understand the real world (and its periphery) which is a target for computer processing, and support the processes that clearly define the image of a business system as requested specifications.
First, let’s reflect back once more on why upper processes are regarded as important.
Think about when a demonstration held right before the development of a business system is just about to be completed. The developers realize at that point there is gap between what the system does and what the customers want, and so they must make some changes. If there are only a few changes to be made, they will be lucky because it will only be a minor inconvenience. In the worst case, however, they will have to extensively overhaul the business program and probably will not meet the delivery date. After having such an experience, people who idealize the waterfall model will more than ever feel that the complete pinning down of the business system image in the upper process is crucial. In contrast, people who recommend development based on the spiral model will probably say that continually making revisions early is important because the complete pinning down of the business system image at an early stage of development is impossible.
There are various ways of thinking, so let’s return to the discussion of the importance of upper processes and try to put ourselves in the position of a custom business program developer. When you take on the development of a custom business program, failing to completely pin down the image of the business system will have dire consequences. The customer will claim that their endless stream of requests that come after the estimate are covered under the original contract, resulting in work that exceeds the original estimate and may drive the development project into the red. That is why the clear definition of requested specifications is crucial to turning a profit.
However, the complete pinning down of the business system image is quite hard work, even for an experienced, highly skilled person. As a result, it would be nearly impossible for software tools to do it. You will be able to better understand this if you imagine the following situation.
At the beginning, customer requests will not always be clear, and sometimes during development, customers will change their mind and want to make changes to their requests. Furthermore, requests may differ between customer (enterprise) departments (there will be differences in values), and as a result the gathering of requested specifications is never easy. Consequently, it is said that talking with the end user is far more important than sitting in front of a computer. It is also said that knowing the mechanism of real intentions (informal system) that cannot be elicited normally is crucial to the development of truly helpful business programs. Since there is a limit to the information that can be obtained through an interview for gathering requested specifications, there are some who are of the opinion that employees must be determined to learn job details and undergo OJT (on the job training). The job of gathering requested specifications is more social science than computer science.
Is it possible to use tools to support this sort of complicated work? It is impossible to approach this directly, and using tools to carry out this sort of work is mostly unthinkable. However, only a portion of upper process work can be supported in some form. The kind of support described hereafter is actually carried out using tools.
• Support for writing documents containing requested specifications that outline the business system image (Word processors)
• Support for writing various types of diagrams (Upper process CASE tools)
• Interview support (Questionnaire based on development know-how for the same type of business system)
• Simulated-experience support (Prototyping support tools for forms and documents)
In addition, there are means of communication, such as e-mail and groupware, and they have an indirect support effect at minimum. However, we will omit them from this book to keep us from diverging too far from our subject. Let’s take a look at each support by the above-mentioned tools.
3.1-c Writing Support
A part of the process of understanding the real world that will be the target of computer processing and outlining the business system image is writing documentation and diagrams. Writing is necessary for leaving a record, and it is also effective in rationally outlining thoughts. The resulting documentation and diagrams may sometimes be kept as formal output, while other times merely temporarily used during work processes. In either case, a certain percentage of upper processes consist of such writing work.
Using a word processor when writing documentation offers major support because it will be easy to add, change, delete, and otherwise edit text. And using a CASE tool diagram editor when writing diagrams (a type of design drawing) also offers major support because the burden of revising tedious diagrams will be lessened.
Not only do support tools have a direct effect by means of their distinct functionality, but they also have a cooperative effect that is obtained by making work fun. No one wants to read illegible handwriting to which lots of corrections have been made, but when you see nice word processor output, polishing the writing becomes enjoyable and you want to unify the format whenever you find parts that are not aligned. For example, we could safely say that this book would not have been completed without a word processor. Rereading one’s own writing is an overwhelming job for people who write illegibly and poorly, but word processors have the power to change it into a fun job.
This sort of cooperative effect is certainly present, but opinions are divided regarding the degree of effect. Remaining cool-headed is of utmost importance because there is also excessiveness in the evaluation of upper process CASE tools that we will talk about hereafter.
Note that although we discussed writing support in upper processes in this section, it goes without saying that similar writing support in lower processes is also possible.
3.1-d Upper Process CASE Tools
CASE is an acronym for Computer Aided Software Engineering, and CASE tools are a general term for tools that support software development. Consequently, CASE tools in the broad sense also include fourth-generation languages (4GLs). However, while the term 4GL gives the impression that it is native to the business field, the term CASE seems to have an academic air about it. The difference in nuance between 4GL and CASE leads many people to think that CASE does not include 4GL.
When a boom occurs, terms end up getting colored, and so when you mention CASE tools without any modifiers, it normally means upper CASE tools that succeeded in the tool business in the latter 1980's in the U.S. and Europe, i.e. upper process CASE tools that support the upper processes of development. In the following paragraphs, we will zero in on such upper stage CASE tools and attempt an across-the-board evaluation of them.
The target of CASE tools is the automation of the upper processes of software development and the automation of programming. Upper process CASE tools that held such an ideal and started supporting the upper processes of development experienced a sudden boom. However, the boom did not last even five years because upper process CASE tools were nowhere close to that ideal, resulting in too large a gap between their ideal and reality. Such a negative evaluation would have been swept away by the boom’s momentum and ignored if it had been staged at the peak of the boom. However, the boom has already passed, so if we were to return to the former battlefield so to speak, and evaluate what has passed, there wouldn’t be any shooting no matter what we said.
First, let’s take a look at what upper process CASE tools actually are.
Starting in the 1970’s in the U.S., professors of software engineering began advancing a variety of style diagrams based on such things as structure analysis. They were based on data flow diagrams (DFD), entity relationship diagrams (ERD), and so on, and were effective for analyzing the structure of business processing.
However, when you try to write a diagram, a number of revisions are required until you can complete it. Often you are briefly delighted that you have completed a nice diagram only to face the tragic reality that you have to totally revise it once you have calmed down. Doing this with a pencil and an eraser is troublesome and will not lead to an attractive diagram. Moreover, it is just not smart.
Upper process CASE tools have revolutionized the writing and revising of diagrams. They have changed it so that you can use the mouse to write and revise graphical diagrams on your PC screen. Upper process CASE tools could be likened to a word processor for diagrams or a CAD (computer aided design) system for writing diagrams. But that is a rather narrow way of viewing them. There were also upper process CASE tools that automate some of the consistency checking for diagram content. However, such checking was not at an intelligent level, but rather was something like a feature found in a word processor for checking the correspondence between the table of contents and body in a document.
Upper process CASE tools certainly are effective for writing support. However, if you evaluate them from the perspective of how much they support the clear definition of request specifications, the answer is not much. For an example of a method for evaluating the degree of support, refer to Appendix 3 “Example Using Build-Up Method to Determine Improvement Rate of Productivity.” To begin with, these sorts of diagrams are certainly not easy to understand for end users who will be judging the adequacy of specifications. However, in the U.S. and Europe, there are analysts who specialize in analyzing requests, and these people write diagrams based on structured analysis and other techniques. These diagrams are effective when specialists are analyzing the real state of business processing. Consequently, we cannot say there is no demand for this kind of tool. Still, it is hard to imagine that this alone would lead to a boom.
If you look into the background and causes of the boom, you will find there was a strong underlying need for improved productivity in business program development, the attractiveness of tools that employ graphical representations, the pleasing sound of the cutting-edge technology of CASE, clever tool vender advertising, and cooperative relationships between computer journalists and consulting firms.
When people like computer journalists were captivated by the attractiveness of CASE tools and started making a big deal about them, information department staff at companies had to obtain a certain degree of knowledge about them because top executives there would ask such things as, “The introduction of CASE tools at other companies have had an effect, but what are we doing?” That led to the purchase and study of CASE tools. However, upper process CASE tools are not easy to understand, and this consequently led to more work for consulting firms. A market consisting of a variety of interrelated people was thereby formed.
We can also add the following. When companies studied CASE tools, it was normally planning department personnel who were involved in establishing the company’s long-term vision that carried out the job rather than those who actually did development work. Such people tend to buy into the notion that CASE tools pursue the ideal. There is nothing inherently wrong with that, but it sometimes leads them to ignore reality and to have overblown expectations, and such expectations may even take on a life of their own.
Once expectations were overblown, it became hard to convince people that the reality was actually different, and once large numbers of people started participating in the business, it became difficult to easily pull out. The only way to proceed from that point was forward, and hence the boom in upper process CASE tools was born.
In due time, many people figured out that their expectations were left unfulfilled, and they soon began joking that upper process CASE tools were neither software or hardware but rather were shelfware (something that just sits unused on a shelf). The boom of the upper process CASE tools died down at the end of the 1980s in the U.S and Europe.
Upper process CASE tools were writing support tools for diagrams intended for request analysis pros, and they were a far cry from the ideals of software development automation and automation of programming. Furthermore, they were not something that just anybody could use in place of experts in a particular field, but rather they could only be used by people with training in structural analysis and so on. You could also say since these sorts of tools only support some work in upper processes, we should refrain from exaggerated language. Of course it is an entirely different story if you were trying to make a profit out of such confusion.
We have so far talked about the circumstances of the upper process CASE tools’ boom. There was a later movement attempting to fuel a boom by introducing integrated CASE tools, but it did not have much success because most people knew that there were not yet any tools, and so on, that were able to truly automate all development work. They may appear one hundred years from now but not in the near future, and thus there is no need to worry about them. Nevertheless, the illusion that they existed was definitely there. The fact that computers are still seen as being in the realm of the mystical and the exaggerated claims by tool vendors probably encouraged such illusions.
Topic 5: Exaggerated Tool Claims
For a period of time, the claim “using tools boosted productivity n times” was being made. This is clearly an overstatement. A look into the multiplication factor reveals it is like instantaneous wind velocity so to speak and only applies to a specific case with favorable conditions. It is almost never a statistically meaningful value. There were also self-serving comparisons that cannot escape mention. Examples included cases where productivity improved because people with development experience for the same types of business programs, or people with extraordinary skill were doing the work and comparisons with normal development where estimates tended to be low. There is no way to easily measure the multiplication factor for productivity, which gives free reign to those who say it is okay if it cannot be ascertained. However, overstatements are easily seen for what they are, and so exaggerated multiplication factors were eventually regarded as advertising propaganda. The lack of any satisfying explanations about how to measure the multiplication factor for productivity is now commonly regarded as advertising propaganda rather than an objective assessment.
For information on measuring the multiplication factor for productivity as objectively as possible, refer to 4.2 “Various Ways of Measuring Software Development Productivity.” At the same time, you should also refer to “Topic 8: How Much Do Tools Improve Productivity?” found in 4.3 “Is Software Development Productivity Improving?”
3.1-e Interview Support
In this section, as a questionnaire we will refer to the question-and-answer document based on customer orders and what was noticed when developing a business system. A questionnaire could be called a sort of collection of know-how for building a business system, but it could also be seen as a tool to use at customer interviews.
If one customer ordered something that another one had ordered in the past, it just might be something any customer would want. Consequently, it is quite effective to interview customers using a questionnaire created based on this. One question could be “In general [meaning other customers], there are such and such choices, so what would you choose in this case?” This will make customers realize things they had never thought of before. Also, asking such questions will allow you to discover ahead of time requests that customers would probably have made at some later date.
However, in the parameter customization of business packages as discussed in 1.1 “Differences between Custom Business Programs and Business Packages,” it is usual to interview customers and then set parameters based on their answers. Since these parameters are information for giving certain attributes to the business package and creating a business system the customer seeks, they can be referred to as a sort of questionnaire for the pinning down of the business system image. On the flip side, you could say a questionnaire for a custom business program corresponds to customization parameters for a business package.
Since any attempt to establish new customization parameters for a business package will be accompanied by work for building in what is necessary, you cannot easily increase parameters. And since there are probably also sales policies that try to avoid customization, a parameter will only be defined after careful screenings.
At the same time, questionnaires for custom business programs aim to comprehend all requested specifications. Far more questions than the number of parameters for business package customization ought to be included, and by simply having customers answer these questions, you should be able to form an image of a business system that is a much better match for the customer than a business package.
As we will discuss later, the need for creative adaptation (NCA) is high in the business field, and so in addition to gaining an understanding through such canned questions, fulfilling various orders from customers will also be important. (NCA will be described in-depth in Chapter 5, but for now, refer to “Keywords for Understanding This Book” for a brief explanation.) However, I think the first logical step in approximating customer requests would be to pin down the image of the business system according to questionnaire answers. It would then be efficient to adapt closely to customer requests through a second approximation stage, third, and so on.
3.1-f Clarification of Requested Specifications Supported by Simulated-Experience
The points of contact between a business program and its end user are twofold as follows. There are almost no other junctions.
• Information in forms displayed on screen and reports that are output; and
• Data input operations while viewing displayed information
At the initial stage of business program development, it is very effective to show end users the style of forms and report forms (including data input operations too if possible) to give them a simulated experience. This is effective because it allows them to verify requested specifications, which tend to be vague on paper, by putting a business system close to the real thing in front of the customer’s eyes. Such simulated experiences are a means of verification that even people unaccustomed to computer systems will find easy to understand, and they are far easier to understand than the diagrams that appear in the descriptions of upper process CASE tools. (Diagrams are significant in other ways, so this is a rather harsh comparison.) A good analogy would be providing replicas and photographs of food rather than a written menu when customers order so that they will know exactly what they will get.
Since this enables end users to have an early simulated experience of a seemingly finished business system, they may realize many things, resulting in a large number of orders, but at least such orders can be dealt with at an early stage. Specification changes occurring in post processes will thereby be reduced.
This sort of simulated experience requires the creation of a prototype system that can be viewed and operated. To that end, prototyping support tools that help the design of form and report form style among other things are used.
As for the timing of the simulated experience, to what degree should the prototype system be operating before it is shown to the end user will be an issue? Obviously forms that respond when operated are better than those that are just for show. However, since doing this makes the creation of the prototype system longer, it will delay the simulated experience. That is why normally the creation of a prototype system is wrapped up at an appropriate point so that the end user can have a simulated experience.
However, if a business system close to the one planned for development has already been developed, giving users a simulated experience of that system will be effective in verifying requested specifications with no problem. An actual system feels much more real than a prototype system that lacks substance. Promoting component-based reuse will make such things feasible. However, this will indicate to the end user that there is a similar business system already in operation, which puts business program development firms in the difficult position of billing only for the cost of what was newly developed. But development by reuse is much more likely to produce a system that will satisfy the customer than haphazard new development. Shifting to reuse-based development instead of paying and billing for development costs will likely change how simulated experiences are given, and this will enable an improvement in customer satisfaction.
3.1-g Magic Applied between an Upper Process and Lower Process
Some prototyping support tools are designated as upper process support tools while others are designated as lower process support tools, but they are essentially no different in content. Yet, if which designated tools is left unclear, caution must be observed, lest the clever words of tool vendors fool us. Specifically, we might mistakenly think software resources (forms, report forms, and programs) that must be developed in lower processes, after upper processes end, can be automatically generated by tools.
If tool vendors were doing this in bad faith, it could be called fraud, but perhaps they are even fooling themselves.
A description of tool vendor misperceptions will follow. Note that the correct perceptions for avoiding being fooled are contained in parentheses, but it might be fun to skip the portion in parentheses the first time.
During development based on the waterfall model, clearly defining requested specifications by simulated experience is upper process work, and hence, creating a prototype system that is required for a simulated experience is also upper process work.
(We must not confuse the waterfall model as an ideal for actual development. It is usual to go back and forth between upper and lower processes in actual development. Since the creation of a prototype system is carried out to accelerate lower process work, it should be regarded as a lower process.)
During development based on the waterfall model, shifting from upper processes to lower processes comes after the clear definition of requested specifications by means of simulated experience.
(When creating a prototype system which is necessary to verify requested specifications by means of simulated experience, there are already many temporary shifts to lower processes. Therefore, it is not the first time shifts are made to lower processes when requested specifications are clearly defined by means of simulated experience.)
Some forms, report forms, and programs that must be developed by lower processes can be automatically generated from the products of the prototype system created by upper processes.
(The conversion of forms, report forms, and programs created for the prototype system, so that they will be available for later work, should not be called automatic generation. It should be called software resource conversion. Furthermore, lower, not upper, processes develop the products created for the prototype system.)
Now we will note the correct point of view as defined by this book to avoid being fooled into thinking that some forms, report forms, and programs would be automatically generated.
Prototyping support tools should be regarded as lower process support tools because they are first used when creating a prototype system, and in the broad sense, they are nothing but support tools for creating a business system. There are cases where prototype systems are created and then abandoned, and others where they are created and then updated through a number of versions until the finished system. In either case, the creation of the prototype system is nothing but the beginning of business system creation, and it should therefore be regarded as lower process work.
However, work that clearly defines requested specifications and is supported by simulated experience is bona fide upper process work. This wording may give the impression that lower and upper processes are being intermingled, but I would like you to think of work that clearly defines requested specifications and is supported by simulated experience as something that is carried out by returning to upper processes after lower processes. In short, after creating the prototype system according to the spiral model, you return to the upper processes armed with that system which you then use to find inconsistencies with the real world and refine the requested specifications for the business system.
Thinking this way will prevent us from being fooled. Up to now there have been people who were fooled into being thankful for this sort of automatic generation. If some sort of conversion processing is required for midterm development products, it should be fulfilled using tools. Care must be taken because easily misleading wording, such as “automatic generation” is used in place of conversion.
If you take the levelheaded point of view of conversion processing for midterm development products, doubts as to whether such conversion processing is really necessary will spring up. One thing that springs to mind is whether conversion processing is even necessary and if so it should be kept to a minimum. For example, if you were to use a prototyping support tool that is marketed as a lower processing support tool, there would normally be no need for conversion processing.
There are similar cases of being easily fooled by claims that conversion from pseudo code to program code is automatic generation. Care must be taken so as not to misunderstand or to be fooled.
Right from the start there is a large gap between upper and lower processes. Furthermore, there are not yet any tools that can automatically generate lower process software resources from upper process information in the true sense of the term. However, you must remain wary because the hopes for such tools create the illusion they exist.
Saying that its just elaborate magic might be unfair conjecture, but there is also a mechanism by which to classify development processes in detail. This book uses the two easy-to-understand categories of upper process support and lower process support, but it establishes a large number of process classifications, such as process 1, process 2, process 3, and so on. There has also been propaganda showing off powerful tools by emphasizing the generation sequence of using the tools to generate what is necessary in process 2 from the output of process 1, generate what is necessary in process 3 from the output of process 2, and so on.
As astute readers will have already noticed, such propaganda applies magic that involves upper process support and lower process support to many processes. Furthermore, such propaganda is reminiscent of the card trick in which a specific sequence (see Note 6) is used to guess what successive cards are. Since software development does not proceed like a belt conveyor, dividing up the processes does not mean it becomes easy. It does not make sense to divide processes into units smaller than our ideas or thoughts. Armed with such doubts, a look into why tool vendors have established such process classifications will reveal that they are convenient for them. It is something like the gerrymandering of electoral districts to get an unfair advantage in an election.
In actual software development, a variety of development work proceeds concurrently even within the mind of individual developers. It becomes all the more complex when there are multiple developers. Finding clever development procedures by classifying development work rather than development processes therein and then utilizing them is meaningful and understandable. However, trying to forcibly conform work to a specific development process sequence will not end up going well. Actual development (see Note 7) involving the creation of something new will not necessarily proceed according to such a process. Consequently, such development process sequences are usually just for form’s sake.
Note 6: Prepare ahead of time using a deck of cards that is face side up. Take the first card, turn it over, and then place it on the other side of the deck. Now in front your audience, say, “I will guess cards one after the other.” Hold up the deck with the first card facing the audience so they can see it while you memorize the card on the opposite end (the end the audience cannot see). Next, bring the deck behind you and place the card you memorized on top of the card you showed the audience. After that, bring the deck back out in front of you and while holding it up to the audience, guess the top card. By repeating this sequence, you can guess one card after the other.
Note 7: In customization work for business programs that use ‘Business Logic Component Technology’ processes are easily established only for those parts wherein the work method is easy to understand, and the amount of work in that case is also easy to estimate. You could call it the effect of eliminating rehashed creation. However, even if you call it rehashed creation, in conventional development that often accompanies certain types of creation, work does not proceed as per the processes.
3.2 Lower Process Support Tools
This section will employ a study of lower process support tools (tools that support the creation of software for building business systems based on requested specifications clearly defined in upper processes) that was carried out as part of the investigation of an RSCA to report how these types of tools have come to be perceived.
3.2-h Trends in Lower Process Support Tools
This is old news, but productivity improvement by assemblers and compilers has been nothing but remarkable. The use of interactive computers has also been extremely effective. The evolution from the use of paper tape and cards to line editors and finally full-screen editors has also greatly contributed to increased productivity. At the leading edge of this evolution have come special editors for laying out forms and report forms, and word processors for writing documentation. These things have greatly contributed to improving productivity as lower process support tools for some time since the beginning of computer history.
Here is a list of the main support for lower process provided by tools:
• Support for conversion from programming language to machine language (assemblers and compilers)
• Support for the creation of design documentation (word processors)
• Support for the layout and design of forms and report forms (special editors)
• Support for the development of prototype systems centered on form and report form layout
• Support for the design of files and databases (special editors)
• Support for the reduction of program lines (fourth-generation languages)
• Support for improving program visibility (chart editors)
• Support for component-based reuse (object-oriented technology and fill-in systems)
• Support for interpretive immediate execution and debugging (interpreters)
• Support for debugging/testing work (debuggers)
• Support for managing development resources
Although they cannot be called tools, the following software resource that can be ranked as a component is crucial for improving productivity.
• A collection of functional routines (general subroutine libraries)
Although the term “design support” was used in the above-mentioned tool list, almost all lower process support tools are centered on taking over from humans the portion of design work that can be mechanically processed, and is thus not really design-like work. For example, assemblers take over from humans troublesome address calculations as well as conversions from machine instruction names to instruction codes. Such calculation and conversion work certainly is not anything related to the main portion of design, but it is true that such work is difficult and troublesome for usual people. Best of all, these tools make computer processing easy. That is why incorporating such tool functionality has greatly contributed to improved productivity.
Since there were a number of seeds (materials, measures, mechanisms, and/or structures) that made computer processing easier and had a major effect in the early days of computer development, incorporating them into tools made it possible to greatly improve productivity. However, the seeds that had a major effect were soon exhausted, and productivity from that point barely improved at all. Compared to the remarkable progress in the early days, productivity growth by tools thereafter was stagnant due to the lack of seeds. A more in-depth discussion of this can be found in 4.3 “Is Software Development Productivity Improving?”
By all rights, we should confront head on the improving of the productivity of intellectual work that forms the heart of design. In short, we should develop tools that have computers rather than people carry out the central part of design work. Unfortunately, there is little hope of this happening.
Accordingly, lower process support tools, i.e. tools for supporting the creation of programs for building business systems, have come to be developed for providing a pleasant software development environment more than for contributing to further productivity. This is similar to how car development proceeded from the maturation of basic functionality to the provision of pleasant passenger space.
Amid our investigation of an RSCA, we identified and studied in detail the following two types of tools out of the previously mentioned list that are particularly focused on productivity.
• Support for component-based reuse (object-oriented technology and fill-in systems)
• Support for the reduction of program lines (fourth-generation languages)
3.2.1 Fill-In Systems
We have already discussed objected-oriented technology in Chapter 2 as being related to the support of component-based reuse. Accordingly, the following paragraphs will report the results of the study carried out for fill-in systems that aim for the componentization of software as part of the investigation of an RSCA.
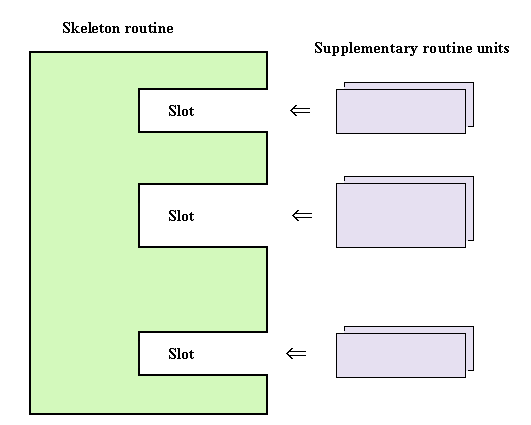
Figure 3-1: Skeleton Routine and Supplementary Routine Units (Hook Methods)
Fill-in systems compose programs from both skeleton routine and supplementary routine units (hook methods) that flesh it out as shown in Figure 3-1. In other words, slots (or hot spots in the current vernacular) are provided within the skeleton routine, and by plugging into them supplementary routine units, we can finish creating a business app. This aims for reuse by using skeleton routines and supplementary routine units as components, and it can be regarded as a sort of component-based reuse system for software.
Since this fill-in system really seems like a synthesis system for components, many names have been suggested from all corners of Japan, and they all are basically the same thing. They include template system, component synthesis system, stopgap system, program paradigm, and so on. SSS has also been regarded as being a sort of fill-in system.
However, fill-in systems other than SSS, all too often ended in failure. This is because two branches can be expected in a fill-in system, and nearly everyone who developed such a system ended up heading in the wrong direction. I would like to introduce the study results for why they headed in the wrong direction.
3.2.1-i First Branch in a Fill-In System
The first branch requires deciding between emphasizing plug-in component synthesis tools or the components themselves. Even if developers of this sort of system vaguely feel the importance of components themselves, once they start tool development, they end up getting sucked into the fun of development. This ends up being an error in judgment at the first branch.
Actually, tools that are plugged in and synthesized have been developed all over the place, but we have never heard of a case where such tools have been skillfully used. The reason for this is components like skeleton routines and supplementary routine units can be any number of things, and therefore, the meaning of the components becomes uncertain. It is like being confronted with a mountain of program fragments of various sizes and various purposes and trying to put them in order only to fail. Such an unordered mess is nothing but useless garbage. Trying to call program fragments components is an exercise in futility.
When that did not fly, some people who were transfixed on tool development resorted to developing a component retrieval system on top of a fill-in system. However, such component retrieval systems were nothing more than systems for retrieving garbage. Garbage can sometimes be useful, but that is about the extent of its worth. There is certainly no guarantee that it will always be useful.
Incidentally, component retrieval systems are also sometimes developed for retrieving components, such as common subroutines, and this is done independent of a fill-in system. Let’s take a look at how component retrieval systems generally end in failure.
Even if you have accumulated component sets consisting of many common subroutines and so on, it is all worthless if you cannot figure out if there is a component you want or you cannot find one you know is there. You would ideally like an easy way to find them. That is why the development of a component retrieval system becomes necessary.
The development of a component retrieval system will not necessarily solve the above-mentioned problems. Most component reuse systems, that accumulated many program fragments, provided a component retrieval system, which then start operating with the statement “Well, let’s use it” have not succeeded. There are many reasons why they did not succeed, but the main reason was users frequently could not retrieve the components they wanted and would thereafter not give the system a second glance. This is the same as tearing out a few pages from a dictionary and calling them a dictionary. Obviously, just a few pages cannot fulfill the role of a dictionary because the words you want to lookup will more than likely not be on the pages that were torn out.
The key to a successful component system is a component lineup in which the components can be found most of the time when users want them. If it is impossible to get so far, then decreasing the number of disappointing search failures by devising a means that allow users to surmise ahead of time whether the component they want is or is not in the component library would be the minimum common courtesy.
Almost no one realizes that the cause of failure lies in this area, but those who were fixated on tools and failed, as well as those who failed in such trials, will recoil at the mere mention of a component retrieval system or fill-in system.
Incidentally, Woodland Corporation emphasized that SSS was a fill-in system in its advertisements, but it seems this ended up being negative publicity because it caused users to back off or misunderstand the product.
Heading in the right direction at the first branch requires emphasizing components themselves rather than tools. No matter how magnificent a component retrieval system or fill-in system you develop, you will not be able to retrieve, plug-in, and then synthesize components that do not exist in the component warehouse. As we already stated, a component lineup is crucial.
To that end, it is important to organize components to a certain extent, develop the necessary components accordingly, and then prepare them so that they are always available. Storing piles of components haphazardly in a component warehouse will not lead to users finding the components they want.
Machine parts and electronic components are all intentionally developed with a specific purpose in mind. The same goes for components of software. Software that is not intentionally developed with a specific purpose in mind and not regarded as a component is junk or garbage without a doubt. Many people have experienced the gathering of many program fragments that were unintentionally developed into components only to find that such a component management system is almost totally useless.
3.2.1-j Second Branch in a Fill-In System
The second branch requires deciding between whether to view skeleton routines, or supplementary routine units, as common components. Since supplementary routine units tend to accumulate, developers of this sort of system are too eager for success and end up thinking that these are common components. Such people end up making an error in judgment at the second branch.
Viewing supplementary routine units as common components is almost the same thing as letting subroutines be common components, and it is zero progress compared to conventional methods. Plugging a supplementary routine unit into a skeleton routine means that the skeleton routine will call that supplementary routine unit. The opposite way of looking at this is the supplementary routine unit will be called to do some type of task by the skeleton routine. This means that supplementary routine units are equivalent to common subroutines.
There are also nitpickers who say, “Supplementary routine units are different from common subroutines,” but if that is true, then saying they correspond to the expansion of macro instructions in assembler and C programming languages is even more fitting. In other words, it is existing technology and no novelty can be found there.
The calling of components in the broad sense involves a variety of means, such as subroutine calls, expansions of macroinstructions, system calls (supervisor calls) and message passing. Plugging in is nothing more than the conventional means of calling components.
Consequently, perceiving supplementary routine units as a common component will not produce a new productivity increase effect. And even if making supplementary routine units a common component does improve productivity, it would simply be a productivity improvement effect produced by a conventional component calling method, and therefore, credit should not be given to the fill-in system. In short, that productivity increase effect is nothing more than the effect of reusing a common component, which was already known to improve productivity.
Since fill-in systems can lead people in the wrong direction at these two branches, it is all too common to end in failure without having any effect whatsoever. However, heading in the right direction at the first and second branches as in SSS, should produce a decent effect. In other words, if you are able to perceive skeleton routines as a common component, new light will come into view. This perception means that the main routine that calls subroutines is actually a common routine, something that was never perceived before. Furthermore, if “common main routines” (called frameworks these days) exist, making them common components will open the way for reusing portions that have thus far been overlooked. In short, since a productivity improvement effect will be achieved in a different area than in the past, we can credit it to the fill-in system.
These noteworthy common main routines are generally not very familiar, but they actually appear in a number of places and contribute to productivity improvements. Calling them a framework in the narrow sense probably makes them easier to understand. Frameworks are also used in fourth-generation languages (4GLs), which have already received much attention, and so we will describe them in detail in 3.2.2 “Fourth-Generation Languages (4GLs).” To become familiar with common main routines or gain an intuitive understanding of them, refer to Appendix 4 “Demarcation of Figure and Ground When Recognizing Something.”
3.2.2 Fourth-Generation Languages (4GLs)
Fourth-generation languages (4GLs) are said to be the descendants of three previous generations of languages in the order of machine language (first generation), assembler language (second generation), and compiler language (3rd generation), but the name 4GL does not always accurately represent what they are. It would be more appropriate to perceive 4GLs as tools or frameworks for improving productivity aimed at the business field than as languages that pursue generality.
There is documentation that lists the ability of end users to use a 4GL or learn it in a certain number of days as criteria for whether a language is a 4GL, but such criteria are not universally accepted. If a vendor calls its product a 4GL, then it becomes one. Because of this, the number of 4GLs is equal to the number of their vendors and easily exceeds one hundred.
Out of the various types of 4GLs, this section will focus on mission-critical 4GLs that can be used to develop custom business programs and business packages in the business field and report the results of the study carried out as part of the investigation of an RSCA.
It is incorrect to contrast cutting-edge CASE with outdated 4GLs. 4GLs are ostensibly included in CASE in the broad sense, and even today most 4GLs contribute to improved productivity. You could even say that many 4GLs were solely designed based on experience in business program development in the business field and thus do not necessarily have any theoretical backing. Another way of saying this is there were many 4GLs that focused on achieving a substantial effect while leaving the question of why they were effective in improving productivity unanswered.
Initial 4GLs improved upon third generation languages, such as COBOL and were reborn as languages that skillfully harnessed the power of relational databases (RDB). There was a different specification at each company, but they all were the same in the sense that they allowed the desired data to be retrieved using a one to two-line statement. Since COBOL required ten to twenty lines to do this, 4GLs were certainly effective.
Furthermore, 4GLs made not only database access, but also database definition easy. When using COBOL to do such things, you have to define both data statements in the program and data items in the database. But with 4GLs, there is no need to perform such redundant definitions.
4GLs have also added the ability to easily define forms and report forms as an extension of database definition. Note that this ability has also played a role in making it easier to develop prototype systems.
3.2.2-k Event-Driven Systems
The products of such early 4GLs were gradually incorporated in third-generation languages as well. The relational database (RDB) access method was standardized as SQL and became usable from the third-generation language COBOL too. And thanks to the capabilities of relational database (RDB) management systems, the redundant definition of data statements in COBOL programming became unnecessary. The gap between third-generation languages and 4GLs was thereby narrowed, resulting in the dilution of the significance of 4GLs. To resolve this situation, 4GLs attempted a comeback by adopting an event-driven system.
In the following paragraphs, we must elucidate why event-driven systems can improve productivity, but first the reader needs to understand what an event-driven system is and how things have changed compared to before and after such systems were adopted.
First off, let’s start with a general explanation. In an event-driven system, when an event related to a certain object occurs, the system runs an event procedure corresponding to the event classification of that object. A good example of an object would be a form or a report form, or a data item within them, while a good example of an event classification would be the classification of an operator’s action.
For example, an event-driven system is characterized by an event procedure running in response to an event such as an operator entering data into a data item on a form or pressing a function key on the keyboard. Associating operator actions with events allows programs to respond to such actions.
Adopting an event-driven system results in a program approach that differs from the traditional programming style for COBOL. Programs must be partitioned into a number of event procedures corresponding to each event classification of each object. Furthermore, the creation of a sluggish program that flows from top to bottom would result in a multitude of lumpy event procedures that run when called if we were to adopt an event-driven system.
This description is probably difficult to understand for anyone except those who know about event-driven systems, so I would like to describe in a slightly easier-to-understand manner how things have changed compared to before and after such systems were adopted. Note that readers with no programming knowledge should refer to Appendix 1 “What Does Running a Program Mean?” to gain the requisite information.
Just like with early 4GLs, programs written in COBOL execute in order starting with the first statement of the main routine and then end at the last statement of the main routine. In addition to this basic flow, COBOL programs sometimes also call and execute a subroutine before returning to the main routine, execute a loop statement, or skip statements to go back or forward. Anyone with even a little bit of programming knowledge will probably see that this kind of program execution method is extremely common and is just like most others.
Programming in the COBOL language is nothing more than the writing of statements comprising main routines and other statement comprising subroutines with the intent of enabling this sort of execution method. Consequently, when developing a program it is necessary to develop both main routines and subroutines, except previously developed subroutines.
On the other hand, later 4GLs that adopted the modern event-driven operation style have basically the same program execution method described above, but at the same time their 4GL programs are different because they are comprised of a multitude of fragments. Another difference accompanying this is that the execution trigger for each fragment is predetermined. The fragments we are talking about here are formally known as event procedures. They are like subroutines that are called as the trigger of an event. The triggering of an event is predetermined, such as the entering of data in an item on a form, and that is what is called and executed. When such a predetermined event actually occurs, the event procedure that serves to process it is called to execute the fragment. The fact that the trigger for executing event procedures (subroutines) is predetermined is something new.
However, the fact that event procedures are being called means that something must be calling them. We will name that something a 4GL operation base. This allows us to say that 4GL operation bases call event procedures and determine the trigger for executing each one.
Assuming this, the development of event-driven programs means the development only of event procedures called from common main routines (a framework in the narrow sense) known as a 4GL operation base, or in other words, the development of only subroutines.
What I would like to stress here is that in the past it was necessary to develop both main routines and subroutines, but with event-driven programs, only subroutines need to be developed.
This change has resulted in increased productivity. In short, the adoption of an event-driven system eliminates the need for main routines that were once routinely developed, and this has raised productivity. Main routines are no longer needed because the 4GL operation base fulfills the role.
3.2.2-l Why 4GL Improves Productivity?
The name fourth-generation language (4GL) gives one the impression that it has magnificent language specifications. However, despite having such a name, later 4GLs do not feature such specifications. An in-depth look into commercially available 4GLs reveals that their language specifications are essentially no different than those in third-generation languages, such as COBOL. For example, the statement equivalent to an IF statement in COBOL is no simpler when you use a 4GL. And while in COBOL you can move a bunch of data all at once simply by writing a one-line CORRESPONDING MOVE statement, there are some 4GLs that do not provide such convenient functionality in their language specifications. This sort of comparative investigation reveals the fact that the language specifications of commercially available 4GLs are not all that different from those of third-generation languages.
Nevertheless, using a 4GL certainly does improve productivity. This was a curiosity to the author. And during our investigation of an RSCA, we eventually realized that fact after we designed a mechanism similar to a 4GL as a trial. The reason for this productivity improvement, as we have already explained, is that main routines no longer have to be developed thanks to the 4GL operation base. A look into 4GL operation bases will reveal they carry out processing related to operation characteristics, and hence eliminate the need to write programs related to operation specifications for business programs. Therefore, you could also say that is what improves productivity. In short, the 4GL operation base becomes the common main routine and takes over operability-related processing, thereby improving productivity.
While 4GLs have the above-mentioned merit, they also are plagued by the following problem of its structure. Specifically, it is often not easy to make slight changes to the operation characteristics of a business program whenever you choose to use a 4GL.
3.2.2-m Two Reasons 4GLs Have Not Gone Mainstream
You would think that 4GLs would be more widely used and have gone mainstream, but that is not necessarily the case. Let’s look into the reasons why.
One problem frequently mentioned by the users of commercially available 4GLs is their frustrating lack of freedom. Any attempt to stray even a little bit from what is covered by a 4GL will end up in a complete denial of support. That is why people often get fed up with 4GLs. The following paragraph details what one developer would say.
“While testing a business program we had developed using a 4GL, the customer requested a slight change in operation characteristics. Since such a change could not be made with a 4GL, we explained that it would be impossible. However, the customer would not understand and we ultimately could not avoid fulfilling their request. We ended up having to put in weekend hours to develop an approximately 4,000-line-long program in a hurry. If we had used COBOL from the start, we could have avoided that fate.”
This typical problem with 4GLs is also sometimes expressed, as “Form styles are limited to those built-into 4GL.” Form patterns, layouts, and operation characteristics are included in form style, and more importantly, operation characteristics are fixed and cannot be easily changed. This can also be thought of as a good thing because it results in standardized operation characteristics. However, almost all programs developed in the U.S. and Europe using 4GLs are incapable of implementing the finely tuned operation characteristics that are encouraged in Japan, and therefore, there are many Japanese who are not comfortable with the operation characteristics of business programs developed using a 4GL.
The reason why operation characteristics cannot be easily changed in 4GLs is that the procedures related to operation characteristics (i.e. the 4GL operation base) is built into the program code generator in the form of wired logic. Changing this would require program customization of the 4GL itself. However, it is safe to say that 4GL vendors would never respond to such change requests in a timely manner.
Another major problem is a lack of standardization resulting in specifications differing with each company. You would think that at least the specifications for the language itself would be standardized, but that is not the case. As in the story of the Tower of Babel, the fragmentation of language creates all sorts of problems. When using a 4GL, you must select one language and learn its new specifications. There are many people who are ambivalent towards the non-standard language specifications of 4GLs even though they would like to use a commercially available version. No one would want to use a confused language up to the point of suffering the punishment of the Tower of Babel.
As you have seen thus far, the crucial point about 4GLs is the operation base that carries out operability-related processing. Consequently, we can think of the specification differences resulting from vendor competition to make 4GL operation bases even better as a necessary evil. However, there is no need for each company to have its own language specification for writing such a simple thing as an IF statement. To the suspicious eye, it would seem that vendors are establishing proprietary specifications in order to enclose users so that they cannot escape.
The open movement is making waves in the computer world, and we have entered a period in which vendors cannot do things simply because they are convenient for their business. Therefore, a continued focus on proprietary language specifications will be the demise of 4GLs. An effort is required to make 4GLs open along the stream of open movement. And the pursuit of openness should lead to the conclusion that we only need to create common main routines (a framework in the narrow sense) that carry out processing related to operation characteristics on top of standardized language specifications.
A blunt opinion concerning this matter is the name 4GL is no good because it gives the impression that it has superior language specifications. I think 4GL development should cease and we should instead quickly replace it with “common main routines” (a framework in the narrow sense). Even if this were to happen, the name 4GL would remain in history as a frontier producing substantial results in light of the experiences in business program development in the business field. Consequently, we hope that the old name will be decisively abandoned and replaced by “common main routine” which is open and easy to understand. Such a frontier spirit is exactly what must be respected.
3.2.2-n 4GL and Fill-In Systems
Now I would like the reader to recall the previously mentioned fill-in systems. 4GLs and fill-in systems that employ an event-driven system are very similar even without a detailed comparison. A comparison of their call-related specifications reveals a 4GL operation base corresponds to a skeleton routine, and an event procedure corresponds to a supplementary routine unit.
The most important similarity is either one is a scheme for reusing common main routines (frameworks in the narrow sense). Any program written in a 4GL that has adopted an event-driven system treats the 4GL operation base as main routines. Therefore, this sort of 4GL can be seen as a scheme for reusing the common main routines known as a 4GL operation base. The same goes for a fill-in system. As we have already said, a fill-in system perceives the skeleton routine as the common main routines (common component), and by reusing it productivity can be improved. In short, a fill-in system too is nothing but a scheme for reusing common main routines.
If you look at the role and function fulfilled by a common main routine, you will notice that a 4GL operation base mainly carries out processing related to operation characteristics. And if you look into what is widely and commonly used as a skeleton routine in a fill-in system, you will find that as you might expect, they are mostly programs that carry out processing related to operation characteristics. In short, 4GLs and fill-in systems are similar in terms of their role and function.
Note that there are a number of other common main routines besides those that carry out processing related to operation characteristics. For example, processing that calls event procedures and supplementary routine units is without a doubt a role of a common main routine. There are also those that carry out database access. Those that are called database tools alleviate the need to create database access programs manually as long as a certain form of usage is followed.
However, visual development support tools for GUI application programs normally adopt an event-driven system. An examination of this matter reveals a GUI operation base fulfills a role similar to a 4GL operation base.
Consequently, the following three programs are “common main routines,” and we can say that their main role is processing related to operation.
• Operation base related to operation specification within SSS
• 4GL operation base
• GUI operation base
3.2.3 From SSS to RRR Family
During the investigation of an RSCA that was carried out before the development of the RRR family, we reconsidered the fill-in system SSS and reevaluated where it was superior. We also compared the event-driven systems of 4GLs and visual development support tools and took the better of each one. This will be described in-depth hereafter.
3.2.3-o SSS as Fill-In System
We have already discussed how most people end up heading in the wrong direction and failing at the two branches found in fill-in systems. We also mentioned how heading in the right direction should produce some degree of success. However, the fill-in system known as SSS fortunately was able to head in the right direction, and it was also able to rack up a huge success, not just a meager one. Let’s take a look at what went right.
In research that Woodland Corporation conducted to develop SSS, the company, as a dealer of office computers had shipped 10,000 business systems to customers, used the systems as research material. Specifically, they carried out their research using the sales management system with the most proven track record as their subject. Let’s discuss the circumstances of the research and the ideas and so on that were produced therein. First, I would like to restate the following paragraph contained in 1.3 “Business Packages with Special Customization Facilities,” and then continue the discussion from there.
If they could standardize program portions related to common specifications and then create only the program portions related to each company’s variety of standards, development work for custom business programs could be rationalized. However, this is easier said than done. There is no clear demarcation between common portions and company-specific portions, and such demarcation is by no means easy to do. (To use the latest terminology, such demarcation is the compartmentalization of frozen areas and hot spots.) Consequently, the ability to cope no matter where company-specific portions are was necessary, and they had to rethink the correspondence between programs and specifications from the bottom up.
During this rethinking, they performed an in-depth study of a sales management system that actually operated rather than investigating component synthesis tools. They demarcated and partitioned the program, turning it into components. This allowed them to head in the right direction of emphasizing components themselves rather than tools at the first branch of the fill-in system.
This book applies the general term reuse system of componentized applications (RSCA) to the component-based reuse system represented by the products SSS and RRR family. This term includes the meaning of a system that reuses componentized applications. If you were asked what a componentized application is, you could say it was an application program that was demarcated and split into pieces. In other words, it means an application program that was broken down into little pieces (i.e. componentized). The important thing here is componentized applications are easy to reuse if the splitting up of components was done skillfully. This is the origin of the term an RSCA, reuse systems of componentized applications.
The idea of demarcation within the rethinking of the correspondence between programs and specifications that was carried out in 1988 came to mind. That was an idea that sprung from the desire to demarcate between programs related to business specifications and programs related to operation specifications. If it were possible to do this, the outlook for research on SSS development could certainly be expected to be brighter.
Since operation specifications are those related to the operation characteristics of a business program, it should be fine to apply the same ones for both Company A and Company B. Therefore, it should be possible to use the same program related to operation specifications. In contrast, business specifications have company-specific portions as well as common portions. This means that programs related to business specifications are what require customization.
Putting all this together leads to the conviction that portions with the highest potential for customization when such demarcation is possible can be narrowed down to only a program of a certain scope.
However, if you look at actual programs, you will see that those related to business specifications and those related to operation specifications are all scrambled up. This means that separating them requires major surgery (refactoring in the current vernacular). Such surgery uses techniques, such as shaping, sorting, and generalization. Since it is something like making numerous changes to the chapter structure of this book to make it even a bit more lucid, talking about the details therein would be too much information and not be very interesting, so we have elected to omit it. In any case, once you look at the post operative-state, you will see that the program related to operation specifications will be a skeleton routine and the program related to business specifications will be a supplementary routine unit.
Since a skeleton routine is a program related to operation, it corresponds to components that we should be able to make common. Consequently, SSS just happened to head in the right direction at the second branch in the fill-in system where either a skeleton routine or supplementary routine unit is viewed as a common component.
In this manner, SSS, which was one kind of fill-in system, provided a scheme for reusing common main routines. In other words, as with 4GLs that adopted event-driven systems, the reuse of main routines that carry out processing related to operation characteristics became something that improved productivity. Furthermore, portions with high customization potential could be narrowed down to only programs related to business specifications written in supplementary routine units.
3.2.3-p Importance of Partitioning Guidelines for Compartmentalization of Components
Amid the emphasis on the need for a component lineup where you can “find the component you want most of the time,” this book had discussed the importance of systematizing components to a certain extent, developing the necessary components accordingly, and then maintaining them so they can be used at any time. In other words, haphazardly saying that this or that is a component without any thought will make it impossible to figure out how to perceive a component and lead to nothing but confusion. It will not be possible to know whether a component you want exists, and for most people, such components will not be easy to use. Making components usable in a methodical manner requires the establishment of strong partitioning guidelines for the compartmentalization of components, systemization of components to a certain extent according to those guidelines, and development of the necessary components according to that system.
In relation to this, I would like to make clear in this book the thinking or standpoint concerning how component-based reuse systems are perceived. For example, when designing a component-based reuse system that is able to synthesize components from a sales management application program, this book takes the point of view that what will be the source of those components must exist within the program that actually runs.
Care must be taken here not to misunderstand. Since application programs for sales management that actually run may be in a spaghetti state, even considerable demarcation to produce compartmentalized blocks will not produce anything that could be called a component. Therefore, we can say without a doubt that surgery (refactoring) is necessary to organize the internal organs through techniques, such as crafting, preparation, shaping, sorting, and generalization rather than mere demarcation and partitioning. If such surgery on a sales management application program is skillfully done, it will result in clean partitions, and each partition will be a component itself or the source of a component. In short, we are thinking about what are ‘Business Logic Components.’ Additionally, the reason for using such vague terms, such as component itself or source of a component, is those; additional components may be required there, functionality will be necessary to be generalized, and some sort of adjustment processing may be required during component synthesis. Basically, as long as the surgery goes well, each partitioned block will become a component itself, and that is what should become a “Business Logic Component.”
What this boils down to is the idea that skillful surgery on application programs for sales management that results in clean partitioning will produce componentized applications for sales management, and this will make it easy to customize them into a sales management system for Company A and another for Company B. In short, reuse will become easier. SSS is nothing other than a real example of this, and it backs up this idea.
At the same time, skillful surgery on an application program for production management to create clean partitioning will result in componentized applications for production management, and this will make it easy to customize them into a production management system for Company A and another for Company B. In short, reuse will become easier.
This is the idea of our book, but how about the perceptions of other component-based reuse systems? For example, there may be other forms different from the previously discussed failures, such as emphasizing component synthesis or emphasizing component retrieval. And pursuing such things may produce some sort of product, but the outcome is obscure. Since it is not possible to attempt the obscure, this book takes the standpoint that there is no other component-based reuse system other than an RSCA. The fact that this concept actually has an effect has been proven by the actual example of SSS.
We could sum this up by saying the perception in this book at least has meaning, and based on this we would not be exaggerating by saying that strong partitioning guidelines for the compartmentalization of components are the crucial key for influencing whether a component-based reuse system is or is not possible.
Accordingly, let’s evaluate SSS from the viewpoint of partitioning guidelines for the compartmentalization of components.
The SSS component set is partitioned into individual ‘Business Logic Components’ based on two partitioning guidelines. The first partitioning guideline is the demarcation of business and operation discussed previously in “SSS as Fill-In System.” The other partitioning guideline is partitioning with data item association discussed in 1.3 “Business Packages with Special Customization Facilities.” In short, these are partitioning guidelines for partitioning by the correspondence of supplementary routine units related to business specifications to data items.
The demarcation of business and operation, the first partitioning guideline, is not unique to the SSS component set but rather is also employed by other tools such as 4GLs. You could therefore say the effect of this partitioning guideline is widely recognized. Based on this guideline, common main routines can be reused and productivity improved, and portions with high customization potential can be narrowed down to a certain range of programs.
Partitioning with data item association, the other partitioning guideline, cleverly perceives the characteristic of specification change requests being represented by data item names in the business field. In 1.3 “Business Packages with Special Customization Facilities,” this book has already stressed the fact that this partitioning guideline has opened the way for building a practical and effective component-based reuse system.
Now I would like to restate the important parts. As for data item components partitioned according to these partitioning guidelines, their correspondence with business specifications becomes clear, and that alone results in meaningful closed blocks, most of which are one hundred lines or less. In addition, they are stereotypically easy to decipher. Furthermore, using names that start with the respective data item names results in easy-to-retrieve blocks. All this has allowed the portioning of application programs into blocks known as components, or more precisely, data item components. This was more than just meager success.
The partitioning guideline of partitioning with data item association would seem to be complying also with visual development support tools at first glance, but the essential point is that one step insufficient to this. The scope of the study did not exactly follow these partitioning guidelines like the SSS component set to the point of foolishness. The SSS component set stuck out in that respect. Since this point is crucial, we will describe it in even more detail a little later in 3.2.3-s “Second Improvement of Partitioning Guidelines for Compartmentalization of Components.”
Incidentally, in relation to partitioning guidelines for the compartmentalization of components, a look at Smalltalk systems, recognized as making reuse easy, reveals they have adopted the guideline of three-way partitioning known as MVC (model view controller) for deciding the configuration of objects that form a hierarchy. Furthermore, the importance of this partitioning guideline is often cited. This is exactly the sort of partitioning guideline that is substantial.
3.2.3-q Improvements for RRR Family
Full-scale development of the RRR family as an RSCA that was positioned as the successor of SSS began in 1995.
In retrospect, since SSS did not differentiate between component sets and component synthesis tools, the RRR family clearly separated them. This book distinguishes between the two by calling the former the RRR component set and the latter RRR tools.
Figure 3-2: RRR Family Components and Component Synthesis
As shown in Figure 3-2, the products belonging to the RRR family, such as RRR Sales Management, are component-based reuse systems comprised of one RRR component set (in this case the RRR component set for sales management) and RRR tools. A RRR component set is a group of components required to construct a specific business program. RRR Sales Management employs the RRR component set for sales management and RRR Financial Accounting employs the RRR component set for financial accounting. In addition, the individual components in a RRR component set are a typical example of the ‘Business Logic Components’ discussed in this book.
When developing the RRR family, we compared the fill-in system SSS with event-driven systems like 4GLs and visual development support tools, and then adopted the best parts of each. The following paragraphs will describe the two main results, namely a call mechanism for components and partitioning guidelines for the compartmentalization of components, which were obtained from that comparison.
As described below, the call mechanism for components is better in event-driven system tools than in fill-in systems.
With a fill-in system, you generally have to modify part of the skeleton routine depending on the number of supplementary routine units that must be put into it. In short, you must delete a slot (or fill it in with a dummy unit) when there is no unit to put into it, and when there are many units that must be put into the skeleton routine, you must increase the number of slots. However, event-driven systems never require such work.
Consequently, it goes without saying we adopted a more modern event-driven system instead of a traditional fill-in system. Note that the parameters during the calling of event procedures were fixed in visual development support tools, but we added improvements to this to raise the degree of freedom in RRR tools.
3.2.3-r First Improvement of Partitioning Guidelines for Compartmentalization of Components
If you take a look at the partitioning guidelines for compartmentalization of components, you will see fill-in systems and tools that have adopted an event-driven system to employ the following two partitioning guidelines as a general rule. The first is demarcation of business and operation, and the second is partitioning of data item correspondence (object correspondence). However, regarding the point of how faithfully partitioning guidelines should be followed; there was a wide gap with the ideal of RSCAs.
No visual development support tools faithfully follow the partitioning guideline of demarcation of business and operation. In visual development support tools, the demarcation of business and operation becomes quite vague, and they rather prioritize on enabling detailed control of hardware operation.
For example, typical events in a visual development support tool are a mouse click on a GUI control or a key press on a keyboard. Rather than saying these are the demarcation of business and operation, it is more appropriate to say they are event architecture that is convenient for controlling hardware devices from application programs as intended. Specifically, to enable different processing when a keyboard key is pressed and when it is released, there is a detailed event architecture that can differentiate between them, and events are made to occur frequently each time a character is entered. In such low-level event architecture, if you tried to create an application program focused on the handling of text input using the keyboard, you would end up having to mix and write operability-related programs containing more lines than the business specification-related program written within event procedure. This does not at all follow the partitioning guidelines of demarcation of business and operation.
However, with even such low-level event architecture, it is possible to separate programs to a certain extent depending on how it is viewed. Take for example the development of an application program for easy-to-use GUI operation. Almost all of the operability-related processing can be left to the GUI operation base, so all that has to be written is the program related to business, mainly event procedures. Visual development support tools generally provide functionality that targets hobby programmers who account for the majority of their users, and they make money by the number of units sold. Using such functionality aimed at hobby programmers makes it extremely easy to create a toy-like program that produces a pigeon when a button is pushed for example. Consequently, we can see that the partitioning guideline of the demarcation of business and operation is being observed for this type of simple program.
However, for programs that perform input processing from a keyboard, as often found in the business field, the partitioning guideline of the demarcation of business and operation as discussed above is almost totally ignored. For example, you might think that being able to move the cursor with the arrow keys is a very basic and simple operation, but doing so requires the writing of a program related to arrow key operation as an event procedure that must describe business processing.
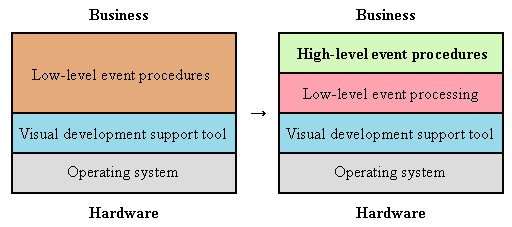
Figure 3-3: Low-Level Events and High-Level Events
Since we wanted to build the RRR family on top of a visual development support tool, we built an event architecture named high-level event on top of a low-level event architecture as shown in Figure 3-3. Furthermore, we made the high-level event architecture faithfully follow the partitioning guideline of demarcation of business and operation.
While visual development support tools are made to cause an event when even a single character is entered for an item on a form, with high-level event architecture we defined an event (high-level event) as the timing at which the entry of data for an item on a form should be checked. Doing so eliminates the need for a program that decides whether a check of data is necessary in any case. You might think this is just a slight improvement, but if you total up all the programs that make such decisions, the number of lines in such operability-related programs (framework in the narrow sense) will surpass those in business processing-related programs. Consequently, there is a major difference in deciding on a high-level event architecture that is convenient for business processing rather than an event architecture that is convenient for the detailed operation of hardware devices. Using high-level event architecture eliminates the need for programming portions unrelated to business processing, reduces the number of program lines for high-level event procedures, and results in easy-to-understand programs.
The bottom line is low-level event architecture tends to intermix procedures related to operation characteristics with programs related to business. On the other hand, high-level event architecture has interfaces for programs related to business, and they eliminate the need to write procedures related to operation characteristics. That is why the number of program lines for portions related to business decrease.
The reason for such an effect can also be interpreted as follows. Since there is a major gap between the low-level event architecture close to hardware devices and the events that appear in the business scene, a large quantity of programs are required to fill the space between them. Accordingly, providing high-level event architecture near the events that appear in the business scene, instead of low-level event architecture, reduces the number of program lines to those necessary for a small gap, and thereby results in easy-to-understand programs.
Although high-level event architecture can produce such an effect, on the other hand it makes the detailed control of hardware devices difficult. Most business programs in the business field need not worry about that, but there is a related problem. The problem is that hardwiring a program, which performs detailed hardware device control, ends up hardwiring operation characteristics. This is nothing other than the problem that was expressed as a “frustrating lack of freedom” in general 4GLs. Note that we will discuss how we confronted this problem in “Topic 6: Tools for a Componentized Event-Driven System.”
One other troubling point about high-level event architecture is its ability to deal with events that appear in actual business scenes. Since low-level event architecture is comprised of detailed events, we know from previous experience that any business scene can be dealt with by assembling such events. On the other hand, high-level event architecture is not all that detailed, which leaves us wondering whether it can deal with business scenes. However, up to this point (about three years following the writing of the initial versions and then seven years after the following revisions), the combining of high-level event procedures has been able to deal with a variety of business scenes with no problems. We cannot say there is no chance of encountering situations that we cannot handle, but if we cannot, we also have the option of adding a new high-level event to the current event architecture. Consequently, there is no problem in terms of the ability to deal with the business scene. This is also backed up by the fact that this sort of problem related to handling ability does not occur in 4GLs that have adopted architecture close to high-level event architecture.
Our discussion of the partitioning guideline of demarcation of business and operation ended up being quite long, so we would like to wrap it up here. Visual development support tools do not faithfully obey these partitioning guidelines. Accordingly, for the RRR family we created high-level event architecture on top of the low-level event architecture of a visual development support tool and it was made to faithfully follow the partitioning guidelines of demarcation of business and operation.
3.2.3-s Second Improvement of Partitioning Guidelines for Compartmentalization of Components
If you take a look at the tools that have adopted an event-driven system and partitioning guidelines for the compartmentalization of components in a fill-in system, you will find that they have adopted a guideline close to the demarcation of business and operation, as well as the partitioning guidelines of data item correspondence (object correspondence). However, regarding the point of how faithfully partitioning guidelines were followed, there was a wide gap with the ideal of RSCAs.
At first glance, 4GLs and visual development support tools seem to follow the partitioning guideline with data item association. Specifically, when an event related to a certain data item occurs, the event procedure corresponding to the event classification of that data item will run. As a result, it would seem that an event procedure was being created per data item. Strictly speaking, an event procedure is created per data item and event classification combination, but if you think of event procedures related to the same data item as belonging to the same group, then partitioning is truly being carried out per data item.

Figure 3-4: Business Program Using a Visual Development Support Tool
However, a vital piece was missing. An event that is crucial to the formation of data item components, i.e. an event related to update propagation, was missing. Because of this missing event, the compartmentalization per event procedure data item became blurred.
As a specific example of this, think of using a visual development support tool to develop a program that supports the entry of orders received data for a product. Specifically, we are talking about the creation of a business program that has a form similar to the one in Figure 3-4. Entering data into the data item named product code in this form will run an event procedure for product code. Within this event procedure, it is common to not only check whether the entered “product code” is in the product master file, but also perform display processing for “product name” and “product unit price.” The problem here is other data item processing, such as “product name” and “product unit price” also end up being carried out within the event procedure for “product code.” This means that the demarcation between data items has become blurred.
There are many inconveniences in such a program. For example, carrying out customization to discount “product unit price” by twenty percent during a product sales campaign for a certain period of time requires changing the event procedure for the product code. Since this is customization for the product unit price, we would like to change the event procedure for that unit price, but that is not how it works. Furthermore, since this event procedure can only be used for forms in which product code, product name, and product unit price appear, the situations in which it can be reused are limited. If possible, we would like to reuse it in forms in which product code and product name appear as well as in forms in which product code, product name, product unit price, and product expiration date appear, but that is not how it works.
Such inconveniences are caused by the blurring of demarcation between data items. The solution is to clearly define the demarcation between data items. This means processing for data items, other than the checking of whether an entered “product code” is in the product master file, must not be carried out within the event procedure for the product code. The display processing for “product name” and “product unit price” should be performed within separate event procedures for the product name and for the product unit price.
This requires a mechanism for starting an event procedure as a trigger for changing the value of other data items. In short, we need a mechanism for update propagation. To implement this mechanism we decided to create event architecture named high-level event on top of the low-level event architecture of a visual development support tool as shown in Figure 3-3. We also added a special high-level event within the high-level event architecture to enable the use of an update propagation mechanism.
As a result, we were able to compartmentalize data item components with good demarcation between data items just like with SSS components. This not only resolved all of the previously mentioned inconveniences, it also lightened the load of development as follows. Whereas SSS required the handwriting of programs for carrying out update propagation processing, RRR enabled them to be automatically generated.
Note that in the automation of this update propagation processing, we employed directed graph theory for one field of mathematics and adopted a system that does not produce unnecessary calls (width first system).
Since event procedures in 4GLs and visual development support tools do not faithfully follow the partitioning guideline of partitioning with data item association, they unfortunately cannot be called components. However, RRR component sets and other methods that faithfully partition event procedures in accordance with data items increase cohesiveness and enable reuse in a variety of situations. They produce component value, and such components can be called ‘Business Logic Components.’ We will call this system that improves upon general event-driven systems and enables event procedures to have value as components a componentized event-driven system. Note that we applied for a patent of this componentized event-driven system.
An evaluation of the event architecture of 4GLs and visual development support tools will reveal the creation of event procedures has not become easy, most likely because their first priority is enabling the creation of any sort of program. In contrast, when designing the event architecture of the componentized event-driven system, we placed an emphasis on the easy creation of event procedures and ease of customization. This required a mechanism for update propagation.
Topic 6: Tools for a Componentized Event-Driven System
RRR tool development was divided between Woodland Corporation and AppliTech Inc. Specifically, AppliTech Inc. handled the adding on of functionality to a visual development support tool to transform it as if it were a componentized event-driven system, and Woodland Corporation handled everything else, which included database access-related work.
In the following paragraphs, we will introduce MANDALA; an add-on tool developed by AppliTech Inc. for the visual development support tool Visual Basic of Microsoft Corporation.
MANDALA, positioned at the core of RRR tools, adopted the previously mentioned componentized event-driven system. In addition, making it an add-on tool for Visual Basic, which is a sort of industry standard, lightened the development load of MANDALA itself. If we had developed all the functionality required by the tool ourselves, development speed would have decreased and we would have not been able to quickly respond to environment changes. There have been many cases of the weight of developing tools for improving productivity bogging down development projects, resulting in the ladder being pulled from under users and causing tremendous trouble. To keep such things from happening, we decided to develop only the functionality lacking in a visual development support tool by creating an easy-to-develop add-on tool.
We paid attention to the following four points in the design of MANDALA:
• Incorporating all 4GL functionality not included in the visual development support tool.
• Creating a structure that could easily deal with customization requests for operation characteristics.
• Enabling not only attractive operation characteristics via a GUI, but also conventional keyboard operation.
• Employing standard language specifications, i.e. not creating local language specifications.
By paying attention to these points, we were aiming for the ultimate open tool by incorporating into MANDALA all functionality considered to be useful in 4GLs. For example, a form application we generated by this tool could be made multifunctional so that it not only could add data to a database, but also carry out processing for viewing, updating, and deleting. As for the problem of the “frustrating lack of freedom” for which 4GLs were despised, we responded by enabling parameter customization for MANDALA. However, there were also cases that this could not handle. Accordingly, we made program customization for MANDALA itself easy and also offered timely support service for developer requests. A “Royal Toolmaker Service” is one AppliTech service for the program customization of MANDALA itself, and we have already offered it for a fee to over ten customers. Note that the average tool vendor does not aggressively carry out tool customization service because they prefer business that does not require constant monitoring just like business package development firms, as discussed in Chapter 1. However, AppliTech Inc. is carrying out this service with information-gathering tactics in mind for customization requests that will enable the adaptation of MANDALA to a wide variety of environments.
We also developed MANDALA as a program generation tool in consideration of such things as the performance of business programs developed by it. Generally, program generation tools can be classified as a pre-generator (software tool) or a post-generator (software tool). Since a pre-generator carries out generation processing ahead of time, developers must make changes to the generation results. A post-generator, however, analyzes developer-written programs and then carries out generation suited to them. Generation tools are frequently said to have many problems, but such problems lie in pre-generators. MANDALA was made into a post-generator that does not have such problems because it can change and regenerate business programs with a high degree of freedom.
For reference purposes, we have listed the main high-level events used by business programs developed by means of MANDALA. The name of each high-level event represents what sort of processing should be carried out in each high-level event procedure. I would like the reader to focus on the high-level event “derived value” therein. This high-level event is related to update propagation.
• Input check (Check): Checks the data entered for the data item.
• Derived value (Derived): Sets the value of the data item upon being triggered by the entry of data in another data item.
• Initial value (InitVal): Sets the initial value of the data item at the completion of each data registration process.
• Guidance display (Prompt): Issues prompt messages for the data item.
• Selection list (SList): Displays a list of possible data entries (selection list) for the data item.
Also for reference purposes, we have listed the main events (low-level events) that can be used in Visual Basic. The name of each event represents what will trigger the calling of each event procedure.
I would like the reader to focus on the difference between low-level and high-level events. In contrast to low-level events that are hardware-dependant, high-level events are directly tied to the business logic of a business program.
• Change: The changing of the objects content is the trigger.
• Click: The clicking of the object is the trigger.
• GotFocus: The moving of the cursor to the object is the trigger.
• KeyPress: The pressing of a keyboard key when the cursor is on the object is the trigger.
• LostFocus: The removal of the cursor from the object is the trigger.
• MouseUp: The releasing of the mouse button when the cursor is on the object is the trigger.
Note that object here means a form or a field (data item) in a form.
Copyright © 1995-2003 by AppliTech, Inc. All Rights Reserved.
![]()
AppliTech, MANDALA and workFrame=Browser are registered trademarks of AppliTech, Inc.
Macintosh is a registered trademark of Apple Computer, Inc.
SAP and R/3 are registered trademarks of SAP AG.
Smalltalk-80 is a registered trademark of Xerox Corp.
Visual Basic and Windows are registered trademarks of Microsoft Corp.
Java is a trademarks or registered trademark of Sun Microsystems, Inc.
===> Chapter 4