Framework and Business Logic Components
CHAPTER 6 Evolution of Life and Component-Based Reuse
Complex systems have become a popular topic of late. In the world of physics in particular, reductionism had been the prevailing concept. It held that we could come to know everything by breaking down matter into its components. However, many people realized this was not true. They began focusing on the fact that when simple components come together to form an organized system, they will end up performing previously unimagined functions. A complex system is a system in which such phenomena occur.
Within research on complex systems, there is the field of artificial life, which seeks to unravel the mystery of life. And within this field, research on the mechanisms of evolution and other subjects is being conducted by equating the DNA information (genetic information) of life forms to information in computer memory.
Based on the idea that the relationship between a program and its functional specification is analogous to the relationship between DNA information and an individual organism, we will refer to the mechanisms of evolution and related subjects as we ponder component-based reuse.
Since this chapter basically consists of a single topic that reinforces this book’s assertions, it should make for some light-hearted reading.
6-a What is Darwin's Theory of Evolution?
DNA had not yet been discovered in the days of C. Darwin, but in this section, we will start by using recent knowledge on DNA and so on to review Darwin’s theory of evolution.
Generally speaking, an individual organism is created according to DNA information, which is equivalent to a blueprint. For the sake of making our description clearer, we will postulate the existence of a biogenesis machine at the risk of somewhat neglecting factual accuracy. Biogenesis using this machine would proceed by inputting DNA information for a monkey to the machine in order to produce a monkey or human DNA information in order to produce a human. As you can see, organisms with different characteristics would be produced depending on the DNA information that is input. In other words, DNA information would serve as a blueprint for the resulting organism. Based on this, an individual organism could be called a genetic phenotype. Now if we say that a program phenotype is its functional specifications, then we can equate the relationship between programs and functional specifications with the relationship between DNA information and individual organisms.
A phenomenon known as mutation plays a crucial role in Darwin’s theory of evolution. A mutation refers to an extremely rare mistake that can occur when DNA information is copied from parent to child. Since a mistake in copying results in different DNA information, the characteristics of the individual organism (genetic phenotype) will differ from the parent.
However, most organisms are conceived via sexual reproduction in which they inherit half of their DNA information from their mother and the other half from their father. Subsequently, the DNA information that the child inherits does not fully match that of the mother or father, and neither does the child’s characteristics match those of the mother or father. Nevertheless, half of the DNA information is a copy of the mother’s and the other half is of the father’s, so the child’s characteristics will still resemble those of the mother and father.
The mechanism of sexual reproduction plays a crucial role in accelerating evolution. However, we would like to set aside sexual reproduction for a while so as not complicate our discussion. Focusing on simple asexual reproduction instead of sexual reproduction will help us highlight the essence of Darwin’s theory of evolution. This is because one hundred percent of the parent’s DNA information is copied to the child in asexual reproduction, which means excluding exceptional cases, the DNA information inherited by the child will exactly match the parent’s. In other words, the child will be a clone of the parent. Consequently, mutations will play a central role in DNA information change, and this will allow us to get closer to the essence of Darwin’s theory of evolution.
Let’s consider the occurrence of copy mistakes (mutations) that cause partial changes in DNA information. As you can easily imagine, there are cases where DNA information is meaningless. Therefore, inputting such DNA information into our biogenesis machine may result in an error, causing the generation of the individual organism to fail. On the other hand, there will also be cases where generation may succeed with no errors, even when copy mistakes occur.
In cases where no errors result, the inputting of the DNA information will generate an individual organism from our biogenesis machine. This individual organism may or may not be adapted to the environment in which it lives relative to other life. There will be an overwhelming number of cases of not being adapted. However, there will also be extremely rare cases of the individual organism being adapted. In such cases, the offspring of the individual organism that received modified DNA information due to copy mistakes should flourish.
Darwin’s theory of evolution says that all life resulted from such a mechanism. In other words, when copy mistakes in DNA information occur and happen to result in an individual organism with a phenotype that is well adapted to its environment, the organism’s offspring will flourish.
There is criticism voiced against Darwin’s theory of evolution that it states extremely obvious facts or it is tautology and does really say nothing of consequence. The offspring of organisms with high environmental adaptability will obviously flourish, and conversely, you could also say the characteristics of flourishing organisms are generally highly adapted to the environment. Consequently, Darwin’s theory of evolution is criticized as not really being a theory at all. However, the essence of Darwin’s theory of evolution lies somewhere else. Specifically, it elucidated the mechanism by which all life results by the accumulation of sudden copy mistakes known as mutations.
6-b Evolution by Copy Mistakes?
Darwin’s theory of evolution can be called a general theory that can also be applied to self-replicating systems besides living creatures. If a mutation occurs in a self-replicating system, something different from what was there before (a mutant) will result. Furthermore, if we apply some sort of filter, such as environmental adaptability to the newly resulting mutant and the previously existing type, only offspring of one or a few types will survive.
Based on this logic, you can understand how evolution might work in this manner, but Darwin’s theory of evolution is actually something that is not easy to believe.
In the case of machines and software, there is always a designer. However, there is no designer for living creatures, such as human beings, which are vastly more complex than machines or software. It is not easy to believe that such complex human beings resulted from accumulated copy mistakes. Mutation is nothing but a completely oblivious designer lacking rhyme or reason. It is like changing designs based on the roll of the dice. You would think that nothing good could result from such randomness, no matter how many mutations accumulated over time.
The author has been involved in software development for some thirty years but has never directly experienced nor heard of program copy mistakes resulting in a program better than the original.
Since leaving this matter unresolved felt unsatisfying, I went hunting for books about the evolution of life and developed an appreciation for biology. There is probably one other reason for the author’s appreciation for biology. At the time, I felt that program development was terribly hard work, and thus if programs could come into being spontaneously according to the theory of evolution, it would make development work much easier, and that fueled the audacity of wanting to imitate such a mechanism.
6-c Natural Selection is Believable
If you look through actual examples of evolution, you will find reports of a phenomenon known as industrial melanism wherein the number of black moths became more numerous than white ones within a certain species during the mid-19 century industrial revolution in Liverpool, England. This phenomenon was the result of the destruction by atmospheric pollution of the whitish lichens that lived on tree bark. The coloration of black moths helped them hide and survive on the blackish tree surfaces that had been exposed. That is natural selection without a doubt. There is also a detailed report on the statistically significant change in the beak width of Galapagos Finches from an average of 8.86 mm to 8.74 mm due to the 1982 to 1983 El Nino effect. The size distribution of the seeds they eat changed due to environmental changes, and natural selection acted on beak size to make it easier for them to eat the seeds.
These are examples of the mechanism of natural selection not mutation within evolution. Moreover, they are examples of natural selection for life that reproduces sexually. In the former example, there originally were genes for white wings and genes for black wings in the moth species, but the individual organisms with genes for black wings increased. In the latter example, there was conceivably some sort of value for getting a gene that decides beak size in Galapagos Finches, but the individual organisms that had genes with values suitable to the environment at that time increased. Such change is in fact evolution, and the accumulation of such subtle differences results in major changes in life.
C. Darwin thought of natural selection as being analogous to artificial selection performed by livestock breeders. Artificial selection performed to improve livestock quality is the singling out and subsequent increasing (breeding) of individual organisms that have gene combinations that are advantageous to humankind. Although natural selection has nothing to do with what is advantageous to humankind, it is nothing more than the singling out and subsequent increase of individuals with gene combinations advantageous for survival. Consequently, we can truly say that natural selection is taking place in the two examples of evolution mentioned above. Strictly speaking, gene frequency change occurring within a species that shares a gene pool is an example of microevolution.
Natural selection and artificial selection are similar to parameter customization. This is because parameter customization is the picking out and subsequent establishing of parameters advantageous to the customer.
The following process would result if we were to carry out parameter customization in a manner similar to natural selection and artificial selection. We would start by creating a particular combination of parameters consisting of a parameter set established for Company A and another established for Company B. It would be like creating child parameters with half the genes for Company A and the other half for Company B and then offering them to the customer. If the customer were satisfied with the parameters, the process would be complete, but if they were not, we would have to create another combination of parameters to offer them. If the combination were still unsatisfactory, we would create another combination of parameters by mixing in a parameter set established for Company C. This could go on and on until the customer was satisfied. We would create an enormous number of child parameters and then have the customer evaluate them. If the customer had enough patience to stick with the evaluation process, this method would be able to identify the combination of parameters that was the most advantageous to them.
The normal method for establishing parameters, that is to say asking customers about each and every parameter, may seem better, but the ability to establish them by the above-mentioned method, modeled after natural selection, could also be believed. But as soon as I came to believe this, my unreasonable dream was shattered. This was because there were probably no customers who would be willing to continue patiently evaluating parameters in such a manner, and I thus realized that it would not be possible to spontaneously create a program by imitating the mechanism of the theory of evolution.
Even if it were impossible to make clients more patient, deciding on a certain adaptability function and then have them evaluate it on a computer would enable us to determine the optimal values by imitating natural selection and artificial selection. This is known as a genetic algorithm, and it is actually applied to optimization problems among other things. For example, the traveling salesman problem — a problem in which you try to find the shortest route for a traveling salesman to visit all designated cities and return to his starting point — presents too many possible combinations for one-by-one comparison, and even computers cannot deal with it. Genetic algorithms can sometimes be effective for such problems. Furthermore, genetic algorithms would likely be effective for the problem of deciding the shape of a bird wing by adjusting various parameters until the most efficient design is achieved. This is because it is thought that birds evolved efficient wings through natural selection, the force behind genetic algorithms.
By thinking in this manner, the author was able to believe that evolution by natural selection, let alone mutation, is entirely possible.
6-d Evolution by Copy Mistakes After All
One day when considering customization of business packages, I starting thinking, “There is also evolution by copy mistakes,” and at that moment I became a believer of C. Darwin. This might be the product of my appreciation for biology or due to a changed way of thinking about programs.
We face not only the problem of selecting optimal combinations from among many parameter combinations, but also the problem of having to create new things to find a solution. It could be compared to the inexorable existence of problems that would be difficult to use as true/false test questions. In this book, we have discussed how low NCA (Need for Creative Adaptation) areas can be solved using parameter customization, but high NCA areas require program customization. Program customization is nothing but finding a solution by creating a new program.
Measures, such as natural selection and artificial selection that are equivalent to parameter customization, are at a loss when dealing with problems that require such new creation. Therefore, some sort of creative activity is required. I also realized it was inconceivable that anything other than mutation is what carries out creative activity, and thus became a believer of C. Darwin. Generally, acting creatively requires wild ideas.
However, the creation of things normally is a very rare occurrence, and such things must therefore be carefully nurtured. Of course when a newly created thing is worthless, it will be abandoned through the mechanism of natural selection. But things that even have a little worth should be retained, and outstanding things should be reused. C. Darwin was saying that outstanding things passed through the filter of natural selection and were widely reused. This is believable.
Now what about the fate of mutation in the case of creation that is neither very good nor bad?
Dr. Motoo Kimura’s neutral theory of molecular evolution, which has already gained acceptance worldwide, maintains that when mutations neither favorable nor unfavorable to an individual organism occur, genetic drift will take place, causing random changes wherein such mutations will either spread to the entire species or fade away. Therefore, mutations that are neither favorable nor unfavorable will be retained only for a certain period of time within the species’ gene pool, or in other words, the component library. They also serve to expand the choices for parameters. Note that the two-chromosome redundancy (i.e. two pairs of DNA information) in each cell can be said to support the formation of a gene pool.
During times when the environment remains constant, mutations that are neither favorable nor unfavorable to an individual organism will settle into the gene pool, thereby enriching its diversity. Then when the environment changes drastically, such mutations will move into the spotlight though natural selection, be culled out, or be retained as always. The meaning of this will become clear if you consider the following. Mutations invent (create) ways to deal with a variety of problems ahead of time, and if they can be retained, they will help in swiftly dealing with any environment changes that occur. In short, this can accelerate evolution because mutations that might be advantageous at a later time have already occurred and have been retained. This is far better than the random occurrence of mutations at the exact time they would be advantageous. If such advantageous mutations are retained, the mechanism of natural selection will do a fine job of spreading them throughout the gene pool through copying in a short period of time if the need arises. Consequently, this advance preparation enables adaptation to new and severe environments far more quickly rather than waiting for mutations that might happen at any time.
Because C. Darwin so overbearingly pointed out the role of creativity in evolution, I had a hard time completely believing it. However, I became a believer of C. Darwin by thinking in the manner discussed above. In the final analysis, you can say that the copy mistakes known as mutations are what play a crucial role in “creation” for evolution.
6-e Speed of Evolution and Component-Based Reuse
The self-replicating system of life that uses DNA information is said to have existed in the Earth’s oceans 3.8 billion years ago. However, any attempts by humankind to make a machine that self-replicates would be far more complex than building a jumbo jet. There are various theories as to how such a complex replicating system spontaneously came into existence, and they form one genre of biology appreciation. If we switch the focus from machines to software, you can see how making something that self replicates would be comparatively easy. Specifically, computer viruses are self-replicating software in the true sense, and 60,000 kinds have already been created. Moreover, several new ones are created each day. You can understand just how indescribably advantageous the molecules that comprise organisms are as the building material for a self-replicating system after comparison to machines and software that self-replicate. However, opinion is still divided as to the origin of such life. Therefore, this book will not delve any further into the matter. We will instead just assume there was such a self-replicating system, just as C. Darwin did. Let’s take an entertaining look at the evolution of life.
Note that the speed of evolution we are talking about here is how fast organisms adapt to an environment. Evolution is nearly synonymous with change in the strict sense and is not necessarily related to progress. Therefore, the transformation of lower animals into higher animals, such as humans, is not evolution. That is why we will consider the question of what needs to be done to rapidly adapt to an environment. Specifically, we will focus on the speed of customization.
The explosive diversification of life is said to have began 600 million years ago in the Cambrian period. This is distinguished from the Pre-Cambrian period in which evolution proceeded gradually for the previous 3.2 billion years. There are various theories as to why diverse life appeared in the beginning of the Cambrian period, but the author thinks that some mechanism for accelerating evolution was acquired (evolved).
One method for speeding up evolution is DNA information exchange. Evolution, by the combination of simple asexual reproduction and mutation, only proceeds sequentially, but with the exchange of DNA information between individual organisms, evolution proceeds in parallel and thereby accelerates. For example, to create something new in an environment wherein no information exchange with other people is possible, you must think up all the necessary ideas yourself, but if it would be possible to exchange information with other people, you could reuse their ideas and thereby speedup your work. It is therefore clear that not only favorable mutations that occurred in a particular individual organism, but also the blending together of favorable mutations that occurred in other individual organisms will accelerate evolution if mutually favorable qualities can be acquired.
The exchange of genetic information is performed by blending DNA information. One of the mechanisms for blending together DNA information in unicellular organisms is a type of sexual reproduction known as conjunction. Another such mechanism is transduction in which DNA information is horizontally transmitted from one cell to the cell of another individual organism, sometimes even crossing the species barrier. Transduction occurs when a bacteriophage, known as a virus infects not only usual organisms but also a bacterium, takes in DNA information from part of a certain cell, and then incorporates itself into another cell. There are a variety of such mechanisms that blend together DNA information, but the author really has no idea which ones functioned efficiently in any particular period. The only definite thing that can be said here is these mechanisms served to accelerate evolution.
Unicellular organisms that acquired such a mechanism diversified explosively as multicellular organisms at the beginning of the Cambrian period. In short, evolution took place. The fact that multicellular organisms evolved from unicellular organisms and took on various forms is just as we explained using the biogenesis machine. That is to say, if we input a variety of appropriate DNA information into the biogenesis machine and then control the machine finely during generation, diverse forms of organisms will be produced. As you are well aware, multicellular organisms employ the mechanism of sexual reproduction to blend together DNA information. Furthermore, a phenomenon known as chiasma wherein the DNA information received fifty-fifty from mother and father is truly blended together takes place.
Gene duplication, which was put forward by Dr. Susumu Ohno as another mechanism that accelerates evolution besides the blending of DNA information, is thought to actually have an effect. Gene duplication says that if a copy of an effectively functioning gene is made ahead of time and a mutation later occurs on that copy, it will be easier to get usable functionality. This resembles one method of component customization discussed in this book, and I can identify with it. For example, you could say that component customization in which we copy the “general customer code component” and then change part of it to create the “important customer code component” is an application of gene duplication. Dr. Susumu Ohno’s well-known idea, which says something to the effect that similar to the evolution of life, the advance of human culture has been dependant on the plagiarism of a small number of creative works, resonates deeply with the promotion of component-based reuse.
Note that for gene duplication, a mechanism for duplicating and copying part of DNA information is required rather than making an exact copy of what is transmitted to offspring. We can also predict its existence based on the need for a DNA information editor. In fact, a mechanism equivalent to an editor that cuts and pastes DNA information is known to exist.
If we were to reduce the history of the Earth thus far into a single year, life would emerge around March, the appearance of multicellular organisms along with the explosive diversifications of life in the Cambrian period would occur in mid-November, the extinction of dinosaurs and the rise of the previously inconspicuous mammals would be in the afternoon on December 26, and humankind would first appear in the afternoon of December 31. Incidentally, computers do not even have a 150-year history equivalent to one second on this timeline. Life at some point acquired a mechanism that accelerated evolution, or in other words, it evolved some sort of tools for increasing efficiency and also reused the products that were created, and I cannot help feeling that this later resulted in an acceleration of the speed of evolution.
Rather than the establishment of DNA as a medium of creation, it was the evolution of DNA information that enabled the formation of a brain that could store and rapidly process information using neurons that guaranteed the acceleration of evolution. In short, the evolution of intelligence in animals epitomized by human beings produced new and different evolutionary trends. Specifically, in addition to genes formed from the medium of DNA, meme that formed from the media of neurons appeared and started evolving almost totally independent of and unrelated to genes.
According to R. Dawkins, who honed one aspect of the essence of evolution with his expression “selfish gene,” a meme is information that is copied through sensory organs and uses neurons as its medium. Examples of meme phenotypes are the opening of milk bottles by the Great Tit and potato washing by the Japanese Monkey. There are many products of culture that could be listed as the meme phenotypes of human beings including swimming styles, agricultural methods, language, religion, flight using hang gliders, the secrets of yacht racing, and programming methods that emphasize plain productivity.
I hope when I use the term meme and speak my mind; the memes based on the content of this book will get on the vehicles known as neurons of many people and flourish, thereby replacing the meme emphasizing plain productivity.
6-f High-Correspondence Portions and Low-Correspondence Portions
We have so far discussed how not only the occurrence of mutations is useful and crucial to accelerate evolution, but also the mechanism for editing and exchanging DNA information, and also the function of gene pools (libraries) that retain DNA information. Now I would like to state my hypothesis that the correspondence between DNA information and its phenotype is also crucial to accelerating evolution. I would like to direct attention to the structure of programs themselves rather than simply focusing on tool types so to speak. To simplify the discussion here, let’s consider the case of asexual reproduction.
Focusing on the relationship of a program or DNA information and its phenotype, and then classifying them into high-correspondence portions and low-correspondence portions, will bring into view something very interesting.
It is thought that in DNA information there are high-correspondence portions that are easy to map to the individual organisms’ organs, which are a phenotype of that DNA information, as well as low- correspondence portions. For example, a genetic map for Drosophila, which is often used in heredity experiments, has been created; enabling scientists to know which part of a gene corresponds to Drosophila eyes, mouth, wings, or other body parts. Such parts can be called high-correspondence portions. Similarly, even in organisms for which no genetic map has yet been created, we can say that certain parts of their DNA information will be high-correspondence portions that clearly correspond to eyes, mouth, and other body parts. However, it seems no one yet knows what part of DNA information is related to the mechanism that controls the generation of Drosophila from egg to adult. Since the correspondence between DNA information and the generation process is complex, I think research in that area will make little progress.
Programs could also be divided into high-correspondence portions and low-correspondence portions. Refer to Figure 6-1. High-correspondence portions can be easily associated with output and behavior (i.e. functional specifications) that can be observed externally, and they are simple to maintain because they make it easy to know what part of a program to fix when trying to change functional specifications. On the other hand, low-correspondence portions are hard to maintain because they make it difficult to establish an association with functional specifications.
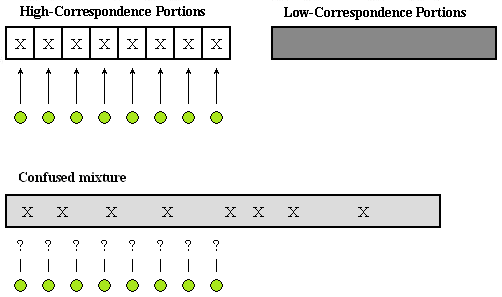
Programs could be divided into high-correspondence portions and low-correspondence portions. High-correspondence portions (X) can be easily associated with outputs and behaviors (i.e. functional specifications) that can be observed externally.
With most programs, there has not been any effort to make high-correspondence portions clear and then extract them, and thus high-correspondence portions and low-correspondence portions are mixed together confusedly for the most part. So, there is no longer a way to clearly associate high-correspondence portions (X) with the functional specifications they correspond to.
Figure 6-1: High-Correspondence Portions and Low-Correspondence Portions
A portion containing code for messages sent by the program can be called a high-correspondence portion as a general rule. However, when messages are assembled in a complex manner, low correspondence is the norm for programs that carry out such processing, and therefore, the message portions too are low-correspondence portions for the most part.
On the other hand, maintenance will become easier if you place all the messages sent by the program in one location and arrange them in an easy-to-understand order, such as alphabetically. This is an example of making high-correspondence portions clearer.
However, many programs can be created to fulfill the same function. That is why programs vary endlessly and become something different due to developers’ ideas and programming methods.
Incidentally, this book explained that it is generally difficult to decipher programs created by someone else, but the basis for this lies in the fact that programs are rich in variety. If you assume programs fulfilling the same function would be the same no matter who creates them, there would be no difference between a program you created and one created by someone else, and thus you could decipher the other person’s program as easily as you could your own. But the truth is no two programs are the same.
Since even programs fulfilling the same function vary endlessly and have all manner of forms, you will end up in deep trouble unless you make a conscious effort to separate high-correspondence portions and low-correspondence portions. Without such effort, high-correspondence portions and low-correspondence portions will end up getting mixed together. Even in information theory, there is a law of increase in entropy. When no attempt is made to make distinctions, a completely confused state will generally result. Consequently, even if there were high-correspondence portions, they would end up being mixed together with low-correspondence portions, resulting in a disorganized state considered as low correspondence.
Let’s suppose that high-correspondence portions and low-correspondence portions are confusedly mixed within the DNA information of a particular individual organism. For example, it would make things easier to understand if there was only one gene corresponding to making body color black, but since DNA information is a confused mixture, let’s assume that the relationship is gene A, gene B, gene C, and so on. Let’s also say that body color can only be black if these genes take specific values. Based on this, evolution that turns the body black would be nearly impossible because there is an extremely low probability of a mutation occurring that would fulfill the conditions of gene A taking value black A, gene B taking value black B, gene C taking value black C, and so on. As a result, such evolution should be nearly impossible.
Based on this, it is conceivable that becoming able to acquire (highly correspond) new traits through a mutation on only a single gene of an organism would be the norm. If there were organisms for which this did not apply, they would either fail to adapt and become extinct, be destined for extinction, or portions that were not that way would have little relation with adaptability. Consequently, we can assume that high correspondence is the norm. Note that the specialization of organism organs appears to be due to the fact that individual organisms, that are a phenotype, are revealed by high-correspondence portions in DNA information.
An even bolder hypothesis would be to say we can predict that the evolution of such portions would be extremely slow because the mechanism that controls generation seems to be of low correspondence. In short, almost all mutations related to generation control are thought to be unable to generate individual organisms. If we equate this with program copy mistakes, it would correspond to the experience of inoperative programs most of the time. However, if one or more mutations occurring on such root portions are acceptable, they might very likely lead to macroevolution which changes the structure of the individual organism.
Now, instead of individual organisms, let’s look at programs and functional specifications, which are their phenotype. Since most programs do not make an effort to clearly reveal and extract high-correspondence portions, we can say that high-correspondence portions and low-correspondence portions are confusedly mixed together.
For example, when adding new functionality to a program, it is usual to have to work on multiple parts of the program at the same time. It is extremely rare to achieve the desired functionality simply by working on one part. This can be seen as evidence of the mixing of high-correspondence portions and low-correspondence portions.
If we could eliminate the confusedly mixed state of high-correspondence portions and low-correspondence portions for programs, achieving the desired functionality simply by working on one part would become the norm, at least for high-correspondence portions. There is a misconception that all programs are difficult to maintain. High-correspondence portions are by nature extremely easy to maintain. Consequently, it would be best to clearly reveal and extract high-correspondence portions. Based on such thinking, the meaning of refactoring becomes believable.
In the living world, confused mixing signifies a state in which evolution is impossible. However, with programs, the human intelligence of the developer lends a hand to evolution, and thus favorable mutations can be provoked simultaneously in many genes so to speak. Thus, even in a confusedly mixed state, programs can be evolved so as to adapt to a new environment. Thus far, no efforts have been made to clearly reveal and extract high-correspondence portions.
Since using ‘Business Logic Component Technology’ results in the clear revealing and extraction of high-correspondence portions, anyone would be able to easily carry out maintenance and customization, at least for high-correspondence portions. This is because normally areas that can be covered by ‘White-box Components’ are high-correspondence portions. You can understand this by recalling “Qualities Required of a 'White Box Component'.” A concrete example of high-correspondence portions is a program related to business specifications that were covered by ‘White-box Components.’ Actually, such portions can be called high-correspondence portions that can be associated with data items.
However, even portions that were thought to be generally high correspondence often can be found to be in a confusedly mixed state when studied closely. For example, in the event procedures of visual development support tools, the correspondence between each control is clear, and thus they are generally considered to be of high correspondence, but they are difficult to reuse easily. Based on this fact, there may be high correspondence from the viewpoint of controls, but from the viewpoint of data items, the partitions are blurred. If there was high correspondence from the viewpoint of data items, reuse of data items (this form of reuse is simple and desired) should be easy. Actually, adopting a componentized event-driven system that provides a mechanism for update propagation helps clearly delimit between data items, enabling data item components that are easy to maintain and customize. This fact was already discussed in “Second Improvement of Partitioning Guidelines for Compartmentalization of Components” within 3.2.3 “From SSS to RRR Family.”
The essence of object-orientation lies in the attempt to emphasize the correspondence with real-world objects when designing software structure. Consequently, the clear extraction of high-correspondence portions and the clear definition of their correspondence with things can be said to be the very essence of object-orientation.
Copyright © 1995-2003 by AppliTech, Inc. All Rights Reserved.
![]()
AppliTech, MANDALA and workFrame=Browser are registered trademarks of AppliTech, Inc.
Macintosh is a registered trademark of Apple Computer, Inc.
SAP and R/3 are registered trademarks of SAP AG.
Smalltalk-80 is a registered trademark of Xerox Corp.
Visual Basic and Windows are registered trademarks of Microsoft Corp.
Java is a trademarks or registered trademark of Sun Microsystems, Inc.