Framework and Business Logic Components
CHAPTER 2 Component-Based Reuse and Object Orientation
The concept of object-orientation has a long history. It is said that its origin can be traced back to the advent of the key concepts of object, class, and inheritance in the simulation language known as Simula67 in the latter half of the 1960’s. Combined with the promotional activities for the object-oriented programming (hereafter OOP) language Smalltalk in the 1980’s, object-orientation became a catch phrase for resolving software development-related problems.
This chapter will report as honestly as possible about how object-orientation has been perceived by looking back at the process of examining the component-based reuse system, as carried out by Woodland Corporation and AppliTech Inc. in 1994. This was the start of development for the RRR (Triple R) family, the successor to SSS.
2.1 Smalltalk System and SSS
Woodland Corporation’s SSS (Triple S) incorporated the good aspects of the concept of a data-oriented approach, but it was developed independently from the concept of object-orientation. However, SSS did have striking similarities with software development in the object-oriented system known as Smalltalk.
2.1-a Software Development on Smalltalk System
It is more accurate to perceive the Smalltalk system as a component-based reuse system that encompasses objects (components) that form a hierarchy rather than a mere OOP language. Actually, experts that can comprehend the objects contained therein, and how they were structured, will be able to immediately develop certain types of visual application programs.
Software development on the Smalltalk system involves the modification of some objects. This choice of words accurately represents the actual state of object reuse. Development consists entirely of modifying declarations of objects and procedure portions or registering modified objects as new objects. In a manner of speaking, it is a system that makes extensive program customization extremely easy. Since object structure in the Smalltalk system was designed after careful consideration, experts who understand that will know where modifications should be made when developing certain types of visual application programs. They also will be able to transform the Smalltalk system into exactly the system they intended simply by adding, modifying, and/or removing some objects.
2.1-b Customization on SSS
SSS, on the other hand, is a business package with special customization facilities for sales management operations (sales management activities) in the business field. SSS includes component sets and their synthesis tools, and these two items comprise a component-based reuse system. Over 5,000 business programs developed using SSS (in short, created as a result of customization) have already been shipped up to 1995.
The strength of SSS lies in its new idea for making customization easy. This is crystallized in the nearly 2,000 SSS component sets in the form of the previously mentioned data item components and their synthesis tools.
The foundation of customization using SSS tools is the selection of data item components. Although I used the term select here, it is not a matter of specifying 2,000 components one by one. Since standard components are selected from among component sets in advance, resulting in a business program that actually operates, you need only to replace a number of components among the standard components, which do not fit customer requirements with appropriate data item components. This is the core work in customization.
The special feature of the data item components comprising SSS component sets lies in the fact that each one is corresponding with a single data item. Since specification change requests are represented by data item names in the business field, it is easy to find the data item component you want from among the 2,000 provided. This is due to the fact that each data item component is assigned a name that begins with the name of the corresponding data item. Please also refer to Appendix 2 “General Features of Business Applications in the Business Field.”
The use of such a naming method using data item names clearly points out which data item components should be replaced or removed when some sort of modification is required. Furthermore, you need only make a single selection from among several candidates categorized by data item names when deciding which data item components to add or use as a replacement. The simple selection of appropriate components in this manner enables the synthesis of a sales management system as intended.
Customization in a business program, which is better fit for specific needs, requires both the internal modification of data item components and new development. Therefore, this involves extensive program customization. During such work, the development of new data item components normally consists of selecting similar data item components from a component warehouse, partially modifying them, and then registering them as new data item components. Obviously, reuse is fundamental to this sort of customization work as well.
In short, the registration of new components and modification of some others strongly resembles program customization work in the Smalltalk system. As previously discussed in 1.3 “Business Packages with Special Customization Facilities,” this book has specially designated this sort of customization as component customization.
2.1-c Ingenuity of SSS Focused on Business Field
If you take a look at the reuse phase of componentized software, you will see component customization is taking place both in the Smalltalk system and in SSS, and the work method in both is nearly the same. It should be noted, however, that SSS has specialized ingenuity only for parts limited to the business field to which it is applicable.
First of all, the ingenuity of SSS tools lies in making selection possible from among several candidates prepared in advance because it makes modification work for ‘Business Logic Components’ even easier. Of course it is easy to establish a similar selection mechanism for objects in the Smalltalk system as well. However, you cannot focus on which objects to make candidates unless you limit the applicable fields. To make selection possible from among candidates, a collection of object and “business logic candidates” is crucial. Since the selection mechanism consists of nothing more than minor ingenuity that almost anyone could think up, which the Smalltalk system will eventually have, the selection mechanism is easy to develop. In contrast, a collection of candidates can only be created through experience, knowledge, and insight related to the kinds of customization that are actually possible.
Secondly, the ingenuity of SSS component sets lies in the extreme ease of identifying components that must be modified. This is because it adopts ‘Business Logic Components’ corresponding with data items as its main components. In the Smalltalk system, it is not easy to identify the objects that must be changed. Identifying these objects requires an expert who comprehends the structure of objects forming the hierarchy contained therein and the contents of each one. This means it will never be as easy for non-experts as SSS is.
In SSS, the good aspects of the shock therapy-like concept of a data-oriented approach deemed to be effective in the business field were incorporated, and ‘Business Logic Components’ were corresponding with data items. As a result, the work for identifying the ‘Business Logic Components’ that must be modified became easy. Note that the methodology of “associating such components with data items” is not guaranteed to work as well in non-business fields, as you can imagine from such a background, but at least it works effectively in the business field.
As a general trend, it seems the Smalltalk system and object-oriented approaches overlook individual improvements focused on specific fields, most likely because they emphasize universal principles and rules. SSS, on the other hand, delves deep into any one of many fields.
2.1-d Applicable Fields for Smalltalk System
Let’s explore the kinds of fields to which Smalltalk is applicable.
If you look at Smalltalk as merely an OOP language, you will see that it aims for generality rather than targeting specific fields. Conversely, if you look at Smalltalk as an object-oriented system that includes objects forming hierarchies, it has an orderly, systematized structure based on the partitioning guideline of Model-View-Controller (MVC), a three-way partitioning method. The applicable field is highlighted by the structural method and the objects that conform to it. Although it is difficult to represent what field this should be called, it is possible to immediately develop certain types of visual application programs.
However, the present Smalltalk system cannot easily develop business programs in the business field. What do you suppose might happen if objects for the business field were to be included in the OOP language of Smalltalk? For example, we could try to make a Smalltalk system for production management business or a Smalltalk system for sales management operations (sales management activities) like SSS. Conceivably, we could end up with a new Smalltalk system for the business field. I would like to attempt something like this if given the chance.
2.2 Reuse System of Componentized Applications and Object Orientation
This section takes a look back at the investigative process before starting the development of the RRR family, the successor to SSS, while reporting how object-orientation was broken down into an easy-to-understand form at one development site.
Since SSS is a “component-based reuse system” that has similarities with the Smalltalk system, we harnessed this strength to carry out an investigation into the RRR family in an attempt to create a system that was more refined than SSS. The concept of object-orientation was a strong focus of our work. To make it acceptable to the greatest number of people, we adopted a policy of conforming to currently popular concepts and tools as much as possible. However, it goes without saying that among the fruits of SSS we attempted to carefully foster anything for which no previous examples existed.
The greater part of the investigation into refining this “component-based reuse system” followed the concept that perceiving the essence of things was more important than separate commercialization. Consequently, it became not only an investigation for a product, the RRR family, but also an investigation into figuring out what a practical and effective “component-based reuse system” should be like. We eventually named the system we were aiming for a reuse system of componentized applications (hereafter RSCA).
Hereafter, the product name “RRR family” and the generic term “reuse system of componentized applications” or RSCA will appear. In short, please think of the RRR family as one example of developing an RSCA into a product.
In addition, a fair number of pages hereafter are devoted to a general description of object-orientation and its peripheral technologies, but this is not the real purpose of this chapter. I would like to once again emphasize the fact that this chapter will report how we perceived object-orientation through an investigation of an RSCA.
2.2-e Two Candidates for Objects
The first problem in applying the concept of object orientation is what to associate with objects. Object-oriented items can be said to be a kind of ideology that exhorts the benefits of preparing a certain structure and then making software conform to a model that follows that structure. Accordingly, what to associate with objects is basically unconstrained. But this does not mean such correspondences can be arbitrarily decided. The benefits of object-orientation cannot be obtained by associating unsuitable things with objects. That is why design and analysis techniques for object-orientation are said to be crucial.
In the investigation of the framework for an RSCA, there were two candidates for what to associate with objects. One was data items, which played a crucial role in SSS, and the other was what is called entities in structured analysis technique.
A concrete example of a data item in the business field is elemental data, such as a “customer code,” “order (received) date,” or “product unit price.” Business programs in the business field normally deal with several hundred to tens of thousands of data items. We have already discussed the fact that a SSS component set is a piecemeal program group corresponding to over 1,000 data items.
Although there are a large number of data items, there is a clear correspondence between business terms in the business field and data item names. In addition, modifications of business content are normally represented using business terms or data item names. Therefore, a data item is a unit of crucial significance in the business field as indicated in the data-oriented approach as well.
The term entity is used in the structured analysis and structured design techniques. Generally, dictionaries define an entity as a being, body, or thing. For example, structured analysis takes up things that should be of interest (things for which you would like to grasp, manage, and control the situation), analyzes what sort of relationship there is between those things, models them in the form of an entity relationship model, and then draws the model as an ER diagram (ERD). An entity is what results from this process. A concrete example of an entity targeting the business field would be a “customer,” “order (received),” or “product.”
Topic 2: What Does Structured Mean?
The descriptive term “structured” is often used when writing about software programming methods. Ever since structured programming, which was advocated by E. W. Dijkstra, gained popularity in the 1970’s, the term “structured” has been extensively used as a catchphrase in solving problems related to software development. Note that later, the status as a catchphrase of this sort was passed on to the descriptive term “object-oriented,” which had an older origin.
To begin with, in order to understand structured programming, we’d like you to read the explanatory text according to the following musical notation that includes its essence. Note that before you read the following paragraphs, I recommend you read through Appendix 1 “What Does Running a Program Mean?” to gain some programming knowledge.
![]()
When you study structured programming, you will encounter the theorem of being able to get rid of the non-structural “go to statement” by using a number of patterns including conditional loop structures, such as while statements. Since this has been mathematically proven, it is fitting to call it a theorem. Later on, we will drive home the importance of using a carefully selected control structure (method of writing statements for controlling program flow), such as while statements or case statements rather than go to statements.
Structured programming has actually had an enormous impact. It can take credit for the standardization of program control structure in an easy to view pattern.
A go to statement is a bad statement that resembles references in a book that tell you to skip ahead to read a certain paragraph in a certain section of a certain chapter. If such statements appear everywhere, the overall book will obviously be difficult to read. A while statement, one of the good statements, instructs a program to, for example, repeat the following calculations every day until the end of the month. It is a control structure that clearly defines under what conditions to repeat and what to repeat and then instructs such repetition. Like the musical notation that instructs repeated performance that appears at the beginning, a while statement is an easy to view control structure. Since a case statement, another one of the good statements, is a control structure resembling itemization, using it will clearly make a program easier to view. In this manner, structural programming has increased the visibility of programs.
However, the control structure known as subroutines, which are contained in such good statements, is effective for the most part, but it is not always easy to view in every case. Subroutines define words packed with meaning so to speak, and then correspond to the use of such words. As a result, it becomes necessary to thoroughly perceive the meaning of those words, and there will likely be resistance to overdoing this. In short, since subroutines for the sake of visibility alone enter the realm of disorganized semantics, the assignment of easy-to-understand meanings and the ability to fully use words packed with meaning become issues.
Note that this book distinguishes between visibility and readability. Readability will be discussed later.
![]()
Structured programming was effective, but of course it alone was not a solution for all problems related to software development. There was still a mountain of issues to be dealt with. Under such circumstances, the preprocess responsibility becomes crucial, and so from the mid 1970’s, the general design carried out in advance of programming had to be structured. The structured design technique was advocated and the revision of analysis work before structure analysis (structured analysis technique) was said to be important. The revision of analysis and general design certainly was necessary, but it did not reveal how analysis and general design could be skillfully structured so that anyone could understand. Consequently, it is not remembered as a loud declaration of victory. The descriptive term “object oriented” emerged during such a period.
2.2.1 Associating Entities with Objects
When the investigation of an RSCA commenced, it was thought that associating entities with objects was closer to the concept of object-orientation that attempts to honestly model the real world. Incidentally, the significance of object-oriented entities does not reside in purpose-orientation, but rather object or entity-orientation. In simpler terms, it emphasizes the correspondence with things in the real world when designing software structure.
There is also continuity from associating entities with objects, structured analysis, and structured design techniques. In addition, it could also be said that entities are similar to normalized tables known to people who know relational database (RDB) theory. Based on these reasons, the association of entities to objects was thought to be safe.
2.2.1-f Object and Instance Variables
When associating entities with objects, attributes which is a term of structured analysis or structured design techniques are equivalent to instance variables (called private member variables in the OOP language C++) in object orientation. They are also equivalent to what are known as columns or items in normalized tables and even data items that play a crucial role in data-oriented approaches and SSS.
Specifically, if you considered a “product” as an object, then the data item that represents an attribute of the product object, such as “product name,” “product unit price,” or “product size” would be an instance variable (or private member variable).
A large variety of terms have suddenly sprung up. The use of synonyms is troublesome because of the different origins of terms despite similar content. It is probably good to rely on familiar words to gain an understanding when unfamiliar words appear. Each and every term differs slightly in emphasis, nuance, and level of abstraction. However, if what terms represent is nearly the same, they can be thought of as being the same. The correspondence between such terms is shown below.
Object-Oriented Terms: Non-Object-Oriented Terms:
Object <===> Entity
≈ Table
≈ Format of a record in a file
Instance variable <===> Attribute
≈ Attribute
≈ Private member variable
≈ Column or field
≈ Data item or item
2.2.1-g But is This Progress?
In one sense, the correspondence of entities to objects borrows from the fruits of structured analysis and structured design techniques, and therefore, one might think that no progress has been made, but that is not entirely true.
Early structured programming had a procedure-oriented concept that was most concerned with structure of the procedures, but it took a major swing to a data-oriented approach emphasizing data analysis, organization, and naming conventions among other things within the later structured design and structured analysis techniques. This shocked those who were interested only in procedures. However increasing interest in object-orientation later forced the pendulum to swing back to a central position where both the procedures (methods in object-oriented terminology) and data portions had to be considered. As a result, we must have advanced one step ahead.
In object-orientation, the meaning of the basic units known as objects within the hierarchical class structure is clearly defined. In addition, objects become highly independent capsules containing data and procedures, i.e. all relevant information, in capsules (know as encapsulation). Encapsulated data undergoes information hiding so that it is not visible externally, allowing the use of objects without having to know their internal details. In short, the boundary between the internal and external tended to blur unless considerable care was taken in traditional programming methods, but with object-oriented programming (OOP), there is no longer the need to clearly define the internal and external, thereby avoiding ambiguity and making programs easy to understand. This had the effect of gathering methods (i.e. procedures) concerning encapsulated data into highly independent blocks. In the past, similar procedures concerning a single piece of data would end up scattered about here and there if you were not careful, but with object-orientation, a procedure and its data are concentrated into a single capsule.
A specific example would be taking the entity “product” as an object, and then applying information hiding to the data item “product name” or “product unit price,” either of which are an attribute of the object, so that it cannot be seen. Then, by preparing methods for the product, such as “product purchasing” or “product shipping,” all processing for the product will be carried out through these methods.
A mere entity contains data items that represent its attributes, but it does not contain a procedure. On the other hand, objects contain both data and procedures, both of which are encapsulated. You could say that comprehensively perceiving data and procedures was progress. This aspect of an object differs from a mere entity.
Here is some supplementary information for those who found it difficult to understand 2.2-e “Two Candidates for Objects.” The correspondence of data items with objects is a point of view that focuses on data items for which methods are associated. The correspondence of entities with objects is a point of view that is focused on entities for which methods are associated, and it means that data items are not exposed (i.e. they are turned into private attributes). Exposing data items weakens the effect of information hiding because it results in the ignoring of object-oriented structure.
Those who are not very interested in object-orientation or find it boring should skip forward to 2.2.2 “Associating Data Items with Objects.” Doing so should present almost no difficulties in the understanding of later explanations.
The above paragraph is equivalent to a go to statement, which is contrary to structured programming, but such paragraphs are extremely rare in this book, so I would like to ask for the reader’s understanding in this matter.
2.2.1-h Effects of Object Orientation on a Reuse System of Componentized Applications
The change in point of view from what was once perceived as entities to objects is undoubtedly progress, but what are the resulting effects on an RSCA? During the investigation of an RSCA, the interest of the members conducting the investigation focused on this point, while keeping in mind the concept of object-orientation.
Object-orientation is generally described as having the effect of improving reusability, increasing efficiency of large-scale development, or increasing reliability, but we cannot gauge the degree of effect from such abstract wording. Often, exaggerated explanations of productivity improvement really only mean an improvement of about 0.1 %. Such a meager effect does not give one much to be thankful for. Object-orientation for the sake of object-orientation is meaningless. A harsh point of view would be that if conventional concepts and models can produce an adequate degree of effect, object-orientation should not take the credit. Consequently, the matter of what really is the advantage of an RSCA compared to those in the past became an issue.
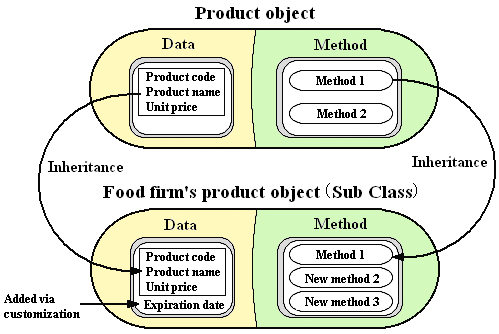
Customization work turns into a refined procedure.
Figure 2-1: Effects of Object Orientation on a Reuse System of Componentized Applications
During the investigation of an RSCA, only one effect of object-orientation was found. After eliminating what was formally achieved by the component-based reuse system SSS and what has no effect visible to the naked eye, only one effect could be found, but it was of considerable value.
The effect was the ability to transform commonplace customization procedures into a refined specification for an RSCA by using an object-oriented structure. Let’s use an example of a product entity, or better yet an object, which is one level higher, to take a specific look at what customization procedures can be transformed into refined specifications. Refer to Figure 2-1.
To characterize objects during design in object-orientation, each object is given one or more attributes (i.e. instance variables). This decides the scope of what sort of processing is possible for each object. Serious consideration is also given to the product object to decide what sort of attributes to give it. For example, attributes such as “product name” or “product unit price” are required in almost all processing, and so they should be built into the product object from the outset as mandatory attributes. The majority of attributes that should be given to the product object in this manner can be brought to light ahead of time. However, since it is not possible to predict all attributes that will be necessary, customization work will be required for adding attributes when you discover that they are necessary. For example, the attribute “product expiration date” might be specially required for a product carried by a food firm, while Company A, a mass retailer of electric appliances, might have customers in 50 Hz and 60 Hz power-supply regions, and therefore, specially require the attribute “power supply type for product” that defines what the default power supply type is (or whether the product is for both types or does not have to be switched). When a special attribute is found to be necessary in this manner, customization work is frequently required to add it to the product.
This sort of customization would be refined in specification when an object-oriented structure is used. Ideally, it would be possible to add/modify/delete methods (procedures of a program) when adding/modifying/deleting product attributes. This ideal can be achieved by using a truly object-oriented structure because object-orientation encapsulates attributes and methods together in one bundle.
In addition, providing a hierarchy, as described hereafter, conveniently opens a road for utilizing the object-oriented reuse mechanism known as inheritance. In short, the definition “food firm’s product object” or “Company A’s (mass electronic appliance retailer) product object” as a subclass (child class) of the “product object” that includes attributes, such as “product name” and “product unit price,” enables the inheritance (reuse) of its attributes (instance variables) and procedures (methods).
Using this sort of object-oriented structure makes it possible to transform customization methods into refined specifications. Note that since SSS tools are poorly organized, this sort of customization work can only be carried out manually through laborious efforts. Issues requiring improvement include not only the above-mentioned problem with SSS tools, but also the ability to deliver refined specifications.
2.2.1-i Reuse System of Componentized Applications and Object-Oriented Technology
It is often said, “What does it mean to apply object-oriented technology.”
There are those that take the harsh view that since Smalltalk is object-orientation in its pure form, object-oriented technology will only be truly applied when a program is written in Smalltalk language. There are also those that say object-oriented technology will be applied as long as some kind of OOP language is used. These are the opinions of people who emphasize programming.
In contrast, people who emphasize object-oriented analysis and design techniques carry out analysis and general design along the lines of the object-oriented concept, and they are of the opinion that an OOP language does not have to be used to apply object-oriented technology, as long as programming is carried out in the spirit of such analysis and design. Also, people who emphasize analysis and general design claim that those who emphasize programming are wrong. They say that the use of the OOP language C++ indicates a program that was developed without using any object-oriented technology. As you can see, there is not always agreement on what constitutes the application of object-oriented technology.
Analysis and general design were carried out along the lines of the concept of object-orientation in the investigation of a framework for an RSCA, but the product version (RRR family) did not use any OOP languages. (Note that the latest version does use OOP languages, such as Java, VB.NET, and C#.NET.) Consequently, whether it should be said that object-oriented technology has been applied to an RSCA, or the RRR family, changes depending on the previously mentioned standpoints. Accordingly, this book says, “The concept of object-orientation was a strong focus in the examination of a framework for an RSCA.” Note that this wording is used because this book attempts to accurately and honestly evaluate object-orientation.
Incidentally, the author has nothing against adding the epithet “object-oriented” in ad copy for products, such as the RRR family. This is because the use of such descriptive terms in advertisements has already become commonplace.
It seems our discussion is returning to square one. The reason no OOP languages and object development support tools were used in the development of the RRR family was no appropriate ones were discovered. If it were merely okay to transform customization work for adding/modifying/deleting attributes into refined specifications, then an OOP language could have been used. However, doing so would lead to rough going in a variety of areas. It would be just like being tormented by the alienation of being treated as a foreigner in an object-oriented system. Although this is the way it is supposed to be in the business field, it is unacceptable in the world of object-oriented systems.
For example, using an object-oriented inheritance mechanism to carry out customization work for adding/changing/deleting attributes makes changes to their related files and databases, but unfortunately, this does not result in a design that enables access with good performance. Since customization is impractical if it leads to a decline in access performance, it is crucial for this sort of customization to not cause any performance problems. However, no object-oriented development support tools that satisfied this requirement were found.
We are not asserting here that object-oriented systems neglect performance. If you take a general look at hardware performance, you will find that compared to the progress made in CPU speed, memory capacity, and disk space, progress in disk access speed has been vastly lower, and therefore, this cannot avoid being a performance bottleneck. This has resulted in an introduction of a variety of software ingenuities to deal with this bottleneck. For example, to improve the performance of object-oriented databases, disk access is decreased by loading all related data into memory ahead of time, processing at high speed without writing to disk each time data is modified, and then by writing to disk all at once, such as when a day’s worth of processing is finished. A variety of such performance considerations are being made.
However, in the business field, the above-mentioned method cannot be adopted because data must be written to non-volatile memory, such as disks, each time a form is processed. When investigating methods to improve the performance of object-oriented systems, it would be desirable to focus on their usage in the business field and then adopt a method that was befitting to it, but that has yet to be done.
Since appropriate object-oriented development support tools were not found, an inheritance mechanism that took into consideration access performance to files and databases had to be developed in-house. Note that a completely object-oriented implementation was not developed, but rather the characteristics of the business field were taken into consideration to develop a special mechanism that reduced the places where object-orientation was thought to be unnecessary. There are many things we would like to try, but there is no point doing so when cost and effect is considered.
2.2.1-j Extended Features Necessary in the Business Field
During the development of the RRR family, features unrelated to the business field were reduced, while on the other hand, those required for the business field were extended. One of the main extended features was related to the customization accompanying the addition/modification/deletion of attributes as previously discussed. In short, improvements were made to increase the inheritance rate with inheriting methods.
Understanding this mechanism requires a certain degree of knowledge about object-orientation, so let’s start with a description of what it is.
Differential programming is one term for object-orientation. This type of programming means, as long as you write subclass-specific procedures (methods) as differences, parent class (super class) procedures will be inherited (can be reused), even if you keep silent thereafter. In short, differential programming is a crucial mechanism for reuse in object-orientation.
In orthodox object-orientation, a procedure in a class is the unit of inheritance, and hence, the unit of reuse. However, during the investigation of an RSCA, problems were found in the commonplace customization discussed earlier, at least in the business field. In short, if the unit of reuse is too large, the rate of reuse will not increase. Since the unit of reuse is the unit of differential programming, we must reuse the whole unit as is. Otherwise, it is necessary to write the entire program (all reuse blocks) rather than only the actual differences.
Generally, making the unit of reuse smaller decreases the number of program lines that must be written as differences and increases the rate of reuse. But that does not mean it is okay to merely make the unit of reuse smaller. Making the unit of reuse too small causes the basic unit to be nearly unidentifiable and makes it difficult to understand the program overall. Consequently, it really makes sense that the unit of reuse in orthodox object-orientation is a procedure in a class.
In the evaluation of whether object-orientation is effective, there are two crucial keys: can it model the real world in an easy-to-understand manner, and do programs (procedures) become easy to reuse? For the former, modeling, the unit of inheritance should be procedures in a class associating with entity, but for the latter, reuse, this is not suitable, at least in the business field. This is because as far as commonplace customization is concerned in the business field, the unit of differential programming in most cases is something associated with data items, which are even more detailed than entities.
For the RRR family, accordingly, the conclusion was reached that it would be best to make what would become procedures associated with data items, through further partitioning the procedures, in a class associating with entity, in accordance with data items, and then make them the unit of differential programming (i.e. the unit of reuse). This also dramatically increases the rate of reuse by inheritance.
The following two sections offer a rather detailed discussion for those who know a lot about object-orientation, or those who have developed an interest in it. If you are not interested, please skip ahead to 2.2.2 “Associating Data Items with Objects.”
2.2.1-k In-Depth Look at Extended Features Considered Necessary
Customization that is commonplace in the business field is concerned with data items that are even smaller than entities. Also, those who are able to add or replace procedures corresponding to data items are able to increase the rate of reuse in the customization of data items.
For example, a method (procedure associated with an object’s class) that displays a product’s attributes will become something different if you carry out customization that adds new attributes to or modifies/deletes existing attributes of a product object.
As a specific example, let’s look at customization wherein the attribute “product repair service center” is deleted and the attribute “product expiration date” is added for “food firm’s product object” of the subclass “product object.” Refer to Figure 2-2. When carrying out this customization, it is necessary to stop displaying the product repair reception desk and start displaying the product expiration date in the method that displays product attributes. Consequently, the method for “product object” cannot be inherited as is. The entire method that displays product attributes must be written as a new method (procedure) for “food firm’s product object.”
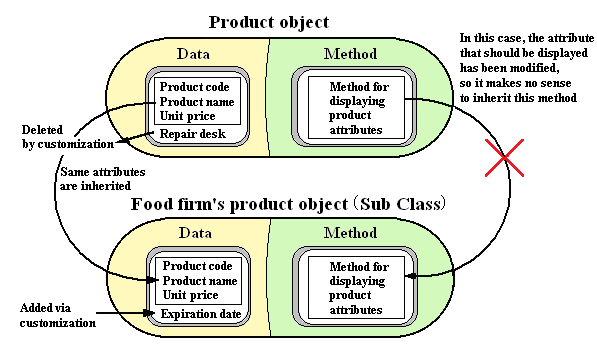
Figure 2-2: Example of Customization Adding/Removing Product Attributes
Since there is only a very small difference, it is not efficient to require that the rather large procedure including the small different portion be entirely written. We would like to increase the rate of inheritance (rate of reuse). The idea adopted in response should be able to raise the rate of inheritance because small, individual blocks are not affected to any large degree, by customization work, if the large method that displays product attributes is partitioned into small methods corresponding to data items.
Since actually associating methods to data items and then partitioning them results in small methods, most of them can also be used for “food firm’s product object,” therefore, enabling inheritance. Consequently, the only new thing that has to be written is the small method that displays the product expiration date, which did not previously exist. This also dramatically improves the rate of inheritance.
The RRR family extension for the business field allows the handling of procedures which are partitioned corresponding to data items, i.e. “small methods,” by using visual and simple indication.
If you were to change your perspective in the investigation of the problem of increasing the rate of inheritance, you would find that it is essentially related to what you should make a method. And when you figure out what you should make a method, you end up returning to the first problem of what to make an object. Let’s take a close look at this.
In object-orientation, generally a procedure associated with an object’s class is said to be a method. Accordingly, if you associated a data item with an object, then a method would be a procedure corresponding to a specific data item from the start. This means there is no need for partitioning a large method in accordance with data items.
If we were to further develop this discussion, you would probably come to understand how it would return to the first problem of what to make an object. We will investigate the correspondence of data items with objects in 2.2.2 “Associating Data Items with Objects,” while in this section we will simply consider the correspondence of entities with objects. If we did not do this, the discussion would end up going in circles, and we would like to avoid that. Despite our saying this, the question of how the following two actions differ might come up, even given the premise of associating entities with objects.
(D) Partitioning a large method in accordance with data items.
(S) Perceiving “small methods” corresponding to data items, for example, displaying product names or product unit prices, as methods from the start.
As discussed above, it is possible to increase the rate of inheritance through carrying out (D). If that is the case, the question is whether it is really the same thing or not, to make “small methods” corresponding to data items as methods (unit of inheritance) from the start, as described in (S). To answer this question, the people who put methods into context must clearly define what stage of development they are in.
If they are in the analysis and general design stage, improving the ability to see the whole picture is crucial. Doing (S) would be completely out of the question because in the business field it would result in an enormous number of methods, thereby worsening the ability to see the analysis and general design. Since methods that display or change individual data items will emerge, there is no choice but to grapple with methods several times the total number of data items. The number of data items handled by business programs in the business field ranges from several hundred to several tens of thousands. This results in having to remain aware of those several methods while conducting analysis and general design.
Since this is very troublesome, we turn procedures associated with entities into methods (unit of inheritance) when conducting analysis and general design. However, since entities are normally a bigger unit than data items, methods too end up being bigger blocks, and so the answer to the previous questions is that the rate of inheritance during customization work cannot be raised without partitioning these big blocks.
2.2.1-l Number of Mismatches with Business Fields
In trying to figure out what should be made a method, the problem arises, whether models that follow an object-oriented structure are a perfect fit for the business field. At present, object-orientation refers to a procedure in a class as a method, and this is used as the unit of inheritance. As a result, the fundamental problem of whether this is appropriate arises.
Although we are not trying to defend object-orientation here, it is appropriate that the method, which is the unit of inheritance, belongs to an object’s class. Since object-orientation emphasizes correspondence with things in the real world, methods relating to such things are made the unit of inheritance. If some pieces smaller than an object were to be arbitrarily made up and then methods were associated with it, the meaning of an object would probably become ambiguous.
However, the situation in the business field differs slightly. In some cases, there are those who want to ignore data items that are smaller than entities (to which objects are associated), but in other cases that has a clearly defined meaning. In short, improving the ability to see the whole picture is crucial, and therefore, the correspondence of entities to objects is easy to understand. However, the rate of method inheritance in customization work will only increase if we associate methods with data items that are smaller than entities. This means that in the customization phase, we require not only methods associated with entities, but also methods associated with data items.
Topic 3: Talking about Instances
The following paragraphs will introduce two topics related to the concept of object-oriented instances.
The first is a discussion about the secondary benefit of object-orientation that was discovered while thinking about what an instance of a product object was.
For example, if you were to consider a business program for the picture gallery industry, instances of a product object would normally indicate individual pictures. If prints were also handled, there would be only a slight difference from paintings. With prints, a number of copies are made from a single work, and therefore, there are two possible ways to handle them as follows:
- Make each copy of the work an instance. (The focus is on each copy.)
- Make the title of work an instance. (The focus is on each work.)
If you wanted to handle print copies that are numbered and signed as individual products, you would probably make each copy of the work a separate instance. If you perceived the prints as a single mass without distinguishing between individual copies and you were only interested in how many you had in stock, you would probably make the product type an instance. In short, you would regard copies of a single work all together as a single product.
It is usual to decide in this manner what to make an instance based on how much of a distinction you want to make. Consequently, a business program for a stationary wholesaler would normally associate a product classification or type (or even a group of special products), such as “pencil B123 manufactured by Company A” as an instance. Such a program would almost never make each pencil a separate instance of the product object.
Generally, when you leave an instance ambiguous during business program development by a large number of people, the results of development would have misunderstandings and confusion. If developers knew object-oriented terminology, they could communicate using special terms like instance, thereby helping to establish a mutual understanding between them. If we were to evaluate this effect in a slightly exaggerated manner, we would say that establishing an object-oriented structure and clearly defining the meaning of its terminology is a secondary benefit.
Another discussion we could have when talking about instances is about the importance of tuning object-oriented features for the business field.
When you use an OOP language, unique identifiers are applied for identifying each instance in a perfectly natural manner. For example, an identifier would be applied to each instance of a product object to distinguish them from other product instances. This may seem quite convenient, but that is not so. Since a code system, such as product codes, has been traditionally used as unique identifiers in the business field, we end up with two of the same thing.
The continued use of product codes as in the past would lead to the existence of two types of identifiers, and such duplication would be a waste. In fact, not only would it be a waste, it would also inevitably lead to confusion because there would be two things charged with the same role. This makes one want to abandon product codes in favor of using only instance identifiers.
In most cases however, instance identifiers are arbitrarily applied by an object-oriented system, and therefore, cannot be systematized ahead of time like product codes can. Also, identifiers are normally not persistent, which means different identifiers might be applied each time you start an application program. For these two reasons, instance identifiers are difficult to use in the business field.
An in-depth look into the inner workings of an object-oriented system reveals there are many that for some reason make instance identifiers out of the memory addresses in their internal tables. This is a problem because it ignores such things as usage in the business field. If we were to recommend object-orientation in the business field as well, then we should by all means make instance identifiers convenient to use just like conventional product codes. Alternately, we should allow most processing to be done using product codes only and not identifiers, even if they exist.
Note that making identifiers persistent in an object-oriented database is a good thing, but identifiers cannot be systematized ahead of time like product codes can. In addition to this, it appears there is the problem of a lack of consideration of usage in the business field. For example, there are many problems with consistency in exclusion control and transaction control, which are necessary in the business field.
2.2.2 Associating Data Items with Objects
The previous section associated entities, which have traditionally been the focus of the business field, with objects, and discussed the investigation and analysis of an RSCA while keeping in mind the concept of object-orientation. This section reports the investigative results of associating data items rather than entities to objects.
Associating data items to objects is convenient because it fits in with the concept of assigning a crucial role to data items, which is a special feature of SSS. However, since this differs from association by the usual object-oriented analysis, we were left wondering what it is. We were worried this was too realistic and might have a weak theoretical basis.
However, in general, we learned that in visual development support tools, there is something close to data items corresponding with objects. Therefore, we were relieved that the correspondence of objects to data items was not unprecedented. In addition, since we wanted to try to use some sort of visual development tools in the development of the RRR family, we gathered the support of the members conducting the investigation for associating objects with data items based on the fact that good conformance with visual development support tools was convenient.
2.2.2-m Object Orientation and GUI Operation
A graphical user interface (GUI) is a method of visual operation using GUI controls (also known as widgets), such as buttons, menu items, list boxes, or text boxes, laid out in a window. The GUI was born at Xerox’s Palo Alto Research Center, further developed by Apple Computer in their Macintosh computers, and finally enjoyed commercial success with the masses in Microsoft Corporation’s Windows operating system. GUI software is successful because it perceives GUI controls as objects, and it is like a child of object-orientation born in answer to our prayers. This section will introduce a GUI program as a successful example of object-orientation.
GUI operation is said to be object-oriented. This is said due to the fact that GUI operation and object-oriented structure have a perfect correspondence with each other as described below.
GUI operation is represented in the form “perform x operation on y,” such as “perform click operation on the menu item,” “perform double-click operation on the icon,” or “perform click operation on the button.” If we associate these GUI controls (menu items, icons, and buttons) with objects, then the operation of “perform x operation on y” becomes “perform x operation on the object.” Furthermore, if we associate this “perform x operation” with a method that has an object, then we can represent all of the above examples as “perform the operation prescribed by the method on the object.” Refer to Note 3.
Note 3: Generally, when this sort of easy-to-understand correspondence exists, i.e. program fragments and things in the real world correspond exactly; the program fragments corresponding to those things become easy-to-identify blocks and are easy to make into what can be called components.
For example, since the various components in the SSS component set can correspond with data items, we can partition a program into easy-to-understand units (data item components). In addition, since GUI operation programs can correspond with GUI operation in the form “perform the operation prescribed by the method on the object,” we can partition programs into easy-to-understand units (components).
GUI operation matches perfectly with object-oriented structure as just described, and that is why the application of object-oriented technology is becoming a fixture in GUIs.
2.2.2-n GUI Operation Base and Processing Programs
Generally, programs related to GUI operation use object-oriented technology, associate each GUI control with an object, and associate the operation of such controls with a method. And when an operator performs an operation on a GUI control, the result is a mechanism in which the method corresponding to the operation on the GUI runs.
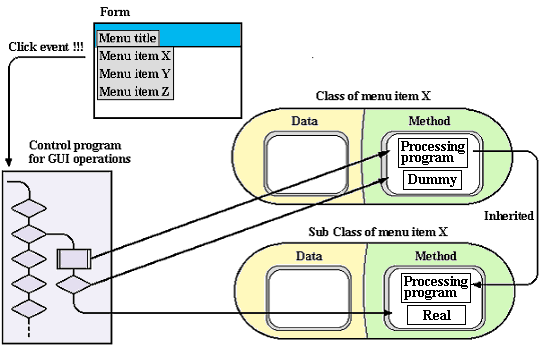
Figure 2-3: GUI Operation Base and Processing Programs for GUI Operation
If you take a look at the development of programs related to GUI operation, you will find that you can classify them into those that form correspondences with objects (GUI controls) and those that do not (those that take the roll of passing on control for example). We know that we can partition the former, i.e. programs that form correspondences with GUI controls, into individual methods for an object.
As shown in Figure 2-3, this book calls the former processing programs for GUI operation, and the latter, which does not correspond with objects, a GUI operation base. Generally, application programs that run on an operating system (OS) are called processing programs, but let’s try to classify GUI operation programs into two categories similar to what was described above.
Classification in this manner results in processing programs for GUI operation that corresponds exactly with the methods of the corresponding object. In addition, a GUI operation base can be referred to as something that passes control (calls) to a method (processing programs for GUI operation) that corresponds to the operation performed by an operator on a GUI control. Moreover, you can also say that a GUI operation base is a program that implements a mechanism upon which methods run.
2.2.2-o Reuse of GUI Operation Base and Processing Programs
Let’s say that when developing a program to achieve a certain objective; we decided to adopt a GUI because we were concerned with operation characteristics. However, developing this sort of program from scratch is a big job due to the fact that we have to develop the program itself (a business processing-related program), and on top of that, develop both a GUI operation base and processing programs. To make this development work easier, it would be convenient to reuse a GUI operation base and processing programs that have already been developed.
Generally speaking, the reuse of programs involves decipherment, which makes reuse very tedious work. However, GUI operation bases and processing programs that use object-oriented technology can be easily reused.
A specific example would be relying on a GUI operation base and click method (processing program for GUI operation that performs standard processes) for most of the processing that has to be performed when the user clicks menu item x. The common processing (required when the user clicks menu item x, or when he/she clicks menu item y) is performed by the same GUI operation base and click method already developed. Consequently, we only need to create a program related to the special processing. In short, we only need to create the business-processing program.
Let’s take an in-depth look at this. After establishing menu item x as menu item subclass, we would write the business processing portion of the program as a click method for the business processing of menu item x. By doing so, the method for menu item x would be inherited in principle as the method for other menu items, and a program written for the difference would be used only for the click method for business processing. In short, we would reap the benefits of having only to write a program for the difference (differential programming).
Another way of looking at this is saying the benefits of object-oriented technology make it easy to perform program customization on processing programs for GUI operations.
This has already been stated earlier, but the use of object-oriented technology makes reuse easier. Developing programs from scratch has some tedious aspects including the need to provide a design of what to associate with objects, but reuse certainly makes the work easier.
2.2.2-p Visual Development Support Tool
A number of types of visual development support tools are currently available. They provide mechanisms for the above-mentioned differential programming and make it extremely easy to develop programs that provide GUI operability.
Visual development support tools often use the terms event procedure or event handler to refer to programs that are written as differences, such as a click method for business processing. An event, for example, is something that happens like “clicking,” and an event procedure is the program that runs when such an event occurs. In addition, visual development support tools have a convenient mechanism for automatically generating subclasses simply by writing an event procedure. Note that an in-depth discussion on event procedures is provided in 3.2.2 “Fourth-Generation Languages (4GLs).”
As you can see, visual development support tools are in almost complete accord with object-oriented structure, but they have fewer features than the object-oriented structure of Smalltalk, which is said to be orthodox object-orientation. They also have portions that have been extended. This should be viewed favorably as a bid to make this easier.
2.2.2-q GUI Objects Corresponding with Data Items
A GUI can be viewed as a stage director (operator) assigning a performance to actors (GUI controls) on a stage (window). In that sort of world, object-oriented structure fits in perfectly, and object-oriented technology has achieved great success.
During the investigation of an RSCA, we considered what we should do to capitalize on this great success. In other words, since sixty to seventy percent of components in the RRR family run when an operator interacts with forms, we felt we were in a similar situation, and the incorporation of GUI operability into the RRR family was essential. To do this, we associated the forms that the RRR family handles with windows, and then we thought it would be good to establish a design that associates input fields within forms with text boxes (a type of GUI control).
Upon actually trying to create a prototype using a certain visual development support tool, we found that although functional tuning was required, there were basically no problems designing in that manner. In short, this was the greatest strength of SSS. We discovered a way for associating data item components with the event procedures of a visual development support tool, and this discovery assured us that we could inherit all of the good aspects of SSS. More information about this is provided in 3.2.3-s “Second Improvement of Partitioning Guidelines for Compartmentalization of Components” within 3.2.3 “From SSS to RRR Family.”
The creation of such a design agrees with the policy of conforming to current popular concepts and tools as much as possible without losing the strength of SSS, which we adopted in the investigation of an RSCA. It also allows the relatively easy development of the RRR family because off-the-shelf visual development support tools could be applied to sixty to seventy percent of RRR-family components.
However, upon seeing the results of such a design, we realized that data items in the RRR family were regarded as objects. In short, data items in the RRR family basically corresponded to data items in business program forms, and therefore, visual development support tools considered them as objects (GUI controls).
We previously thought that regarding entities as objects was good, but over the course of our investigation that included visual development support tools, data items ended up being objects.
2.3 How Has Object-Orientation Been Perceived?
This section will report how object-orientation has been perceived through the investigation of an RSCA. It will also state our conclusion as to whether we should associate either entities or data items, which we have investigated thus far, with objects.
2.3-r Object-Oriented Structure
We have already provided an overview of object-oriented structure in “But is This Progress?” under 2.2.1 “Associating Entities with Objects.” The following paragraphs provide a slightly more in-depth description of object-oriented structure, in preparation for an evaluation of object-orientation. Note that readers who are not interested in object-orientation may skip this part.
Object-oriented structure is frequently described using the example of a system that controls a robot’s actions using levers on a remote control box, much like the control of a marionette. This seems to be an easy-to-understand description. Therefore, I would like you to think of a system that controls a robot. For example, you could think of the robot contests held between technical colleges and universities (events in which robots compete in ball games and so on) that are currently so popular.
It is a crucial point in this sort of system to design the robot’s behavior depending on its purpose. In this case, we should start by bringing them to light. In object-oriented terminology, the lever operation required to produce behaviors is known as a method, and thus, we could also say “start by bringing methods to light.” In addition, each method can correspond with a behavioral element we want the robot to produce, such as shoot the ball or move forward. In short, the operation of levers on a remote control box enables the production of such elemental behavior.
Incidentally, in the business field, it is usual to associate elemental processing, such as the registration of a product or the displaying of attributes of a product, as a method for product objects of a sales management system.
To use a word familiar in the programming world, a method is a procedure that performs certain processing (or produces a certain behavior) for an object. In simpler terms, you could think of it as a subroutine that performs some sort of processing for an object. Strictly speaking, a method is something that defines an object’s behavior.
The strength of object-orientation lies in its encapsulation of data and methods so that they can be comprehensively perceived. This can also be seen as a means for preventing data and procedures from being haphazardly scattered about a program. In addition, this imposes constraints so that data referencing and modification are only possible via methods. This is none other than an established mechanism for information hiding that resulted in developments even in non-object-oriented areas. With the inclusion of these matters, object-oriented structure can be discussed in the following manner.
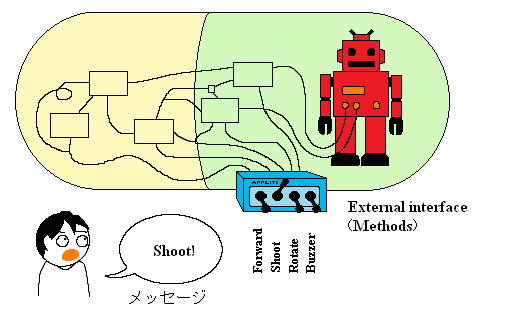
Information hiding is applied so that you cannot
see the complex structure within the object
Figure 2-4: Object-Oriented Structure
When you clearly define and transmit an object name, method name, and parameters as a message (an object-oriented term that means a form of correspondence like a letter), they are conveyed to the target object, resulting in the implementation of the stipulated operation by the specified method. For example, transmitting a message for displaying a product’s attributes that clearly defines the object name “product” and method name “display product attribute” will result in the implementation of the stipulated display processing by the specified method.
There is no way to manipulate an object other than a method. As a result, it is not possible to directly manipulate or reference an instance variable within an object. When designing a robot system, you consider how you want to manipulate objects, and the operations required to make this work as you intended must all be built-in as methods ahead of time. Consequently, when you view an object from the outside, it will look like the previously mentioned remote control box because you will only see the methods on the outside, not the complex content within the object. The end result is skillful information hiding. And since parameters for each method are predetermined, the object’s external interface can be said to be only its methods and their parameters. In short, the scope of an object’s behavior is prescribed by the methods and parameters you provide.
You could probably understand this better if we were to add the following discussion about a robot. The remote control box is for controlling the robot features equivalent to methods, and whenever the operator changes lever settings, messages are conveyed to the robot, causing it to produce a certain behavior. The only thing that can be done to the robot externally is to change the settings of the control box levers, and it is therefore clear what the external interface is. The direct manipulation and observation of the robot’s internal workings are prohibited. Therefore, the operations that can be performed on the robot are clearly determined by the types of levers provided on the control box.
What we have discussed here is the main structure for object-orientation. Refer to Figure 2-4. Note that there is also the reuse mechanism known as inheritance, as previously mentioned.
Object-oriented structure can also be represented using the following extremely familiar terms in the field of conventional software. However, the following representation eliminates special items called actors or active objects, which operate asynchronously, and targets only normal sequential processing.
An object is comprised of common subroutines and structures that group together its internal variables (instance variables). The common subroutines can be called externally, but the direct referencing or manipulation of the internal variables is never permitted. In other words, information hiding is applied so that only common subroutines are visible from the outside. The application of such a mechanism clearly determines the object’s external interface as being the common subroutine and its parameters. In addition, object behavior is clearly determined by the type of common subroutine that is provided.
There are some who will criticize such a representation as desecrating the abstract definition of object-orientation, which is rich in meaning. When you use familiar terms, there is the risk of being influenced by their tone and misinterpreting them in that narrow sense. What we are trying to say is that if you attempt to make the correspondence between each term and things in the real world profitable without being affected by stereotypes and then leaving some room for abstractness to allow a broad interpretation is crucial.
Although there are some who say this, there are others who defend representation in familiar terms saying that if you were to conform to the spirit of object-orientation, there would be no need to be particular about the form of implementation. For example, if they do not fixate on the form of implementation by saying a common subroutine might be a function, an inline-expanded macro instruction, message passing, or a message queue and its process (task), then they are acknowledging that even expressions using familiar terms increase understanding. Conversely, they criticize it as inadequate wording that the characteristics of object-orientation are in message passing. It is true that message passing has an advanced mechanism known as dynamic binding to people in the know, but the strength of object-orientation is not epitomized here.
2.3-s Evaluating Object Orientation
We have ended up presenting a rather in-depth discussion, but it seems that the more in-depth we go, the further we move away from the essence of object-orientation. Plenty of in-depth books have already been written. However, even if they go more in-depth than this book, it does not mean that doing so will clearly reveal the effects of object-orientation. Since in-depth descriptions frequently exaggerate small effects, they just might actually make it difficult to see the true merit of object-orientation.
If you take a second look at the essence of object-orientation, we think you will find that it lies in the emphasis of the correspondence between things in the real world and programs. Assuming this, we cannot help feeling that the more in-depth the discussion, the more limited will be the actual system that is a perfect match and fewer chances there will be for reaping the benefits of object-orientation. We will discuss the above in Chapter 6 “Evolution of Life and Component-Based Reuse.”
It has been mathematically proven that in structured programming, the control structure of all programs can be written simply by combining recommended patterns, such as while statements. In addition, many people are experiencing the fact that standardization of this type of control structure results in easy-to-view programs.
This is not so with object-orientation. First of all, it has not been mathematically proven that the real world can be entirely represented by models conforming to object-oriented structure. Secondly, although there have certainly been reports of successful examples, such as the application of object-orientation making the correspondence between programs and things in the real world easy to understand, this has yet to be experienced by large numbers of people, and there seems to be no guarantee of success in all cases. Even after acknowledging that proving whether this becomes easy to understand would be difficult because it involves subjective elements, we still have to report a large number of convincing examples of both successes, as well as failures, at minimum. Since object-orientation has some abstract and difficult-to-understand aspects, a clear understanding of how it is effective in specific cases (or all manner of cases) will probably only come about after we have many clear-cut examples.
2.3-t Entity or Data Item: Conclusion
Amid the investigation of an RSCA (one example of evaluating object-orientation), there seems to be sufficient reason only for the associating of either entities or data items to objects.
When you associate entities with objects, information hiding is applied to data items, resulting in a tidy and improved view, but when performing customization, you must keep data items in mind, resulting in the loss of most of the effects of information hiding. On the other hand, when you associate entities with objects, customization-conscious implementations are possible and you can perform information hiding per data item, but the view when performing analysis and general design worsens and information hiding per entity becomes nearly impossible. Refer to Note 4. Consequently, when performing analysis and general design, associating entities with objects seems to be the better idea, and if you get to the software implementation stage, then associating data items with objects seems to be the better idea.
Note 4: There are some OOP languages that support an object hierarchy that allows objects within objects. Using object hierarchy enables two-way correspondence that allows objects to be associated with data items within objects associated with entities. However, even if two-way correspondences are made, usage in the business field normally requires the exposure of objects (data items), which means to make the objects public, thereby making information hiding for each entity almost impossible. In other words, this is almost no different than the correspondence of data items with objects. Therefore, in this book, two-way correspondence is considered the same as the correspondence of data items with objects.
Object-orientation has the concept of class hierarchy, and you could probably rank “product unit price” (a data item) as a subclass of the class “product” (an entity). However, doing this breaks the easy-to-understand relationship that says “product unit price” is an attribute of “product.”
Thinking this way ended up making us worried that we had to choose between entities or data items.
Our ultimate conclusion was there is no need to worry because both have meaning. This is because there are many viewpoints from which business programs can be perceived, and when you look from a certain viewpoint, you can make a suitable model from it, but the resulting model will not necessarily be the best one when seen from other viewpoints.
For example, let’s consider whether a virus should be perceived as an organism or a crystal. Depending on how we perceive it, the concept system (model) for gaining a deeper understanding will differ. From the viewpoint that it is an organism, we could use the model of evolution to gain a deeper understanding, and from the viewpoint that it is molecules; we could use the model of crystals to gain a deeper understanding. Consequently, you could say that both of the perceptions are fine.
Similarly, we thought it would be good if there were suitable models for two situations. The first situation is when you are able to see from the standpoint of improving the view when performing analysis and general design for that actual state of business that will form a background for a business system in the business field in order to clarify requested specifications. The second situation is when you are able to see from the viewpoint of implementation so that business programs will have an easy-to-reuse format based on those request specifications. In addition, we arrived at the idea that associating entities with objects is suitable based on the former standpoint of performing analysis and general design with an improved view, and that associating data items with objects is suitable based on the latter viewpoint of implementation so that business programs are easy to reuse.
Note that when you associate data items with objects, it is thought there is no need for features that supposedly must be extended in the RRR family, i.e. features for further partitioning procedures in a class in accordance with data items. Actually, however, a feature for binding data items and entities is required instead of these features. In short, regardless of whether the focus changes to entities or data items, the need for some type of extension related to these features in the RRR family does not change. The necessary features are still required regardless of whether the point of view changes.
2.3-u Impressions of Object-Orientation Concept
Since there are many terms unique to object-orientation, we investigated an RSCA while keeping in mind those that are object-oriented after we came to correctly understand them. If this investigation had targeted another field besides business, or more precisely, if it had targeted a field in which object-orientation could easily play an active role, then we probably would have ended up with a different impression about object-orientation. However, it did target the business field. In any event, there is no disputing the fact that we got some sense of object-orientation through this investigation. In closing this chapter, we will summarize what we sensed through this investigation.
First, when talking about object-orientation itself, we think that using models that conform to object-oriented structure is generally effective. For example, the field related to GUIs is an archetype that fits in perfectly with object-oriented structure and thus achieves an effect. However, this structure alone cannot deal with the circumstances in individual fields, so might we also require creative actions for adjusting it to them? Regarding the business field in particular, there were areas ill suited to object-oriented structure, and we therefore felt that there needed to be extensions focused on usage in that field.
Next, when talking about object-oriented development support tools, such as OOP languages, it appears as though convenient features and performance tuning have been inadequate for the business field. Object-oriented technology has probably fallen into the vicious cycle of not being employed in the business field because it has not become easy to use, and not becoming easy to use because it is not being employed. If that was not the case, object-oriented technology would be used much more in the business field based on the over 30-year history of object-orientation.
Another way to look at this is the functional tuning of object-oriented development support tools for the business field probably ends up hindering generic object-oriented structure. In short, reducing object-oriented features as was done while developing the RRR family dilutes the strength of object-orientation. We also feel that it converges toward something close to development support tools specialized for the business field, such as fourth-generation programming languages (4GL).
From the standpoint of tool vendors, selling what will be object-oriented development support tools for the business field will clearly result in competition with pre-existing development support tools specialized for the business field. However, many object-oriented development support tool vendors have appeared to avoid this by targeting other markets.
In conclusion, when you talk about the epithet “object-orientation,” you need to be careful because sometimes people implement what can be implemented without using any object-oriented technology whatsoever and then rant on as if it was a great achievement of object-orientation. Using an actual development project as an example, we felt the need to debate with vendors about how well certain things improve compared to cases where object-oriented technology is not used. For example, it would be good to get to the bottom of the matter by asking questions, such as how class libraries differ from usual libraries, or how object-oriented databases differ from multimedia databases. In addition, striving to grasp the reality of this without being influenced by words is more important than anything. Alternately, ignoring the epithet “object-orientation” would be another solution.
We have so far ended up dedicating considerable space to object-orientation. To date, there have been a variety of declarations stating,” the effectiveness of object-orientation has been belatedly verified even in the business field.” However, we think little has been written about concrete trials and evaluations from the user’s end or from those who have gotten their feet wet and are forced their approval. That is why we thought it worthwhile to write honestly about what we perceived in the process of investigating an RSCA, and this caused us to go into considerable depth.
Rumors, sweet talk, and appearances alone do not deepen understanding. Pointing out a concrete example and then carrying out a discussion based on it is crucial. Accordingly, our intention was to write honestly from various perspectives on what exactly we did and felt. If you think there are any misunderstandings or we overlooked something, please send an e-mail message to bring the matter to our attention.
Copyright © 1995-2003 by AppliTech, Inc. All Rights Reserved.
![]()
AppliTech, MANDALA and workFrame=Browser are registered trademarks of AppliTech, Inc.
Macintosh is a registered trademark of Apple Computer, Inc.
SAP and R/3 are registered trademarks of SAP AG.
Smalltalk-80 is a registered trademark of Xerox Corp.
Visual Basic and Windows are registered trademarks of Microsoft Corp.
Java is a trademarks or registered trademark of Sun Microsystems, Inc.
===> Chapter 3